Microservices With Spring Cloud Kubernetes


Spring Cloud and Kubernetes are the popular products applicable to various different use cases. However, when it comes to microservices architecture they are sometimes described as competitive solutions. They are both implementing popular patterns in microservices architecture like service discovery, distributed configuration, load balancing or circuit breaking. Of course, they are doing it differently.
Kubernetes is a platform for running, scaling and managing containerized applications. One of the most important Kubernetes component is etcd. That highly-available key-value store is responsible for storing all cluster data including service registry and applications configuration. We can’t replace it with any other tool. More advanced routing and load balancing strategies can be realized with third-party components like Istio or Linkerd. To deploy and run applications on Kubernetes we don’t have to add anything into a source code. The orchestration and configuration is realized outside an application – on the platform.
Spring Cloud presents a different approach. All the components have to be included and configured on the application side. It gives us many possibilities of integration with various tools and frameworks used for cloud native development. However, in the beginning Spring Cloud has been built around Netflix OSS components like Eureka, Ribbon, Hystrix or Zuul. It gives us the mechanisms to easily include them into our microservices-based architecture and integrate them with other cloud native components. After some time that approach had to be reconsidered. Today, we have many components developed by Spring Cloud like Spring Cloud Gateway (Zuul replacement), Spring Cloud Load Balancer (Ribbon replacement), Spring Cloud Circuit Breaker (Hystrix replacement). There is also a relatively new project for integration with Kubernetes – Spring Cloud Kubernetes.
Why Spring Cloud Kubernetes?
At the time we were migrating our microservices to OpenShift the project Spring Cloud Kubernetes was in the incubation stage. Since we haven’t got any other interesting choices for migration from Spring Cloud to OpenShift consisted in removing components for discovery (Eureka client) and config (Spring Cloud Config client) from Spring Boot application. Of course, we were still able to use other Spring Cloud components like OpenFeign, Ribbon (via Kubernetes services) or Sleuth. So, the question is do we really need Spring Cloud Kubernetes? And what features would be interesting for us.
First, let’s take a look at the motivation of building a new framework available on Spring Cloud Kubernetes documentation site.
Spring Cloud Kubernetes provide Spring Cloud common interface implementations that consume Kubernetes native services. The main objective of the projects provided in this repository is to facilitate the integration of Spring Cloud and Spring Boot applications running inside Kubernetes.
In simple terms, Spring Cloud Kubernetes provides integration with Kubernetes Master API to allow using discovery, config and load balancing in Spring Cloud way.
In this article I’m going to present the following useful features of Spring Cloud Kubernetes:
- Extending discovery across all namespaces with DiscoveryClient support
- Using ConfigMap and Secrets as Spring Boot property sources with Spring Cloud Kubernetes Config
- Implementing health check using Spring Cloud Kubernetes pod health indicator
Enable Spring Cloud Kubernetes
Assuming we will use more of the features provided by Spring Cloud Kubernetes we should include the following dependency to our Maven pom.xml. It contains modules for discovery, configuration and Ribbon load balancing.
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-kubernetes-all</artifactId>
</dependency>
Source code
The source code of the sample applications is available under branch hybrid in sample-spring-microservices-kubernetes repository: https://github.com/piomin/sample-spring-microservices-kubernetes/tree/hybrid. In the master branch you may find the example for my previous article about Spring Boot microservices deployed on Kubernetes: Quick Guide to Microservices with Kubernetes, Spring Boot 2.0 and Docker.
Discovery across all namespaces
Spring Cloud Kubernetes allows to integrate Kubernetes discovery with Spring Boot application by providing implementation of DiscoveryClient. We can also take advantage of built-in integration with Ribbon client for communication directly to pods without using Kubernetes services. Ribbon client can be leveraged by higher-level HTTP client – OpenFeign. To implement such a model we have to enable a discovery client, Feign clients and Mongo repositories, since we use the Mongo database as a backend store.
@SpringBootApplication
@EnableDiscoveryClient
@EnableFeignClients
@EnableMongoRepositories
public class DepartmentApplication {
public static void main(String[] args) {
SpringApplication.run(DepartmentApplication.class, args);
}
}
Let’s consider the scenario where we have three microservices, each of them deployed in a different namespace. Divide into namespaces is just a logical grouping, for example we have three different teams responsible for every single microservice and we would like to give privileges to a namespace only to a team responsible for a given application. In communication between applications located in different namespaces we have to include a namespace name as a prefix on the calling URL. We also need to set a port number which may differ between applications. Spring Cloud Kubernetes discovery comes with help in such situations. Since Spring Cloud Kubernetes is integrated with master API it is able to get IPs of all pods created for the same application. Here’s the diagram that illustrates our scenario.
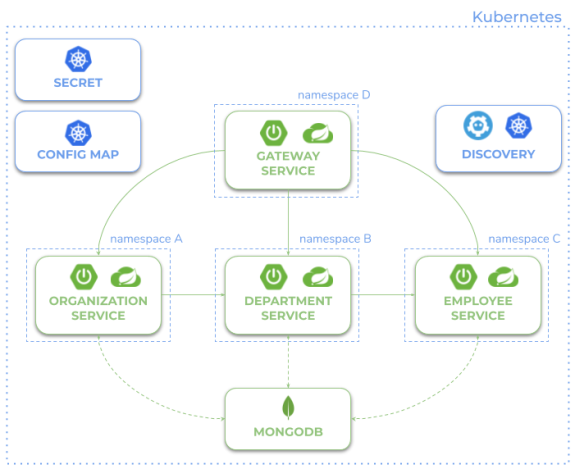

To enable discovery across all namespaces we just need use the following property.
spring:
cloud:
kubernetes:
discovery:
all-namespaces: true
Now, we can implement the Feign client interface responsible for consuming the target endpoint. Here’s a sample client from department-service dedicated for communication with employee-service.
@FeignClient(name = "employee")
public interface EmployeeClient {
@GetMapping("/department/{departmentId}")
List<Employee> findByDepartment(@PathVariable("departmentId") String departmentId);
}
Spring Cloud Kubernetes requires access to Kubernetes API in order to be able to retrieve a list of addresses of pods running for a single service. The simplest way to do that when using Minikube is to create default ClusterRoleBinding with cluster-admin privilege. After running the following command you can be sure that every pod will have sufficient privileges to communicate with Kubernetes API.
$ kubectl create clusterrolebinding admin --clusterrole=cluster-admin --serviceaccount=default:default
Configuration with Kubernetes PropertySource
Spring Cloud Kubernetes PropertySource implementation allows us to use ConfigMap and Secret directly in the application without injecting them into Deployment. The default behaviour is based on metadata.name inside ConfigMap or Secret, which has to be the same as an application name (as defined by its spring.application.name property). You can also use more advanced behaviour where you may define a custom name of namespace and object for configuration injection. You can even use multiple ConfigMap or Secret instances. However, we use the default behaviour, so assuming we have the following bootstrap.yml:
spring:
application:
name: employee
We are going to define the following ConfigMap:
kind: ConfigMap
apiVersion: v1
metadata:
name: employee
data:
logging.pattern.console: "%d{HH:mm:ss} ${LOG_LEVEL_PATTERN:-%5p} %m%n"
spring.cloud.kubernetes.discovery.all-namespaces: "true"
spring.data.mongodb.database: "admin"
spring.data.mongodb.host: "mongodb.default"
Alternatively you can use an embedded YAML file in ConfigMap.
apiVersion: v1
kind: ConfigMap
metadata:
name: employee
data:
application.yaml: |-
logging.pattern.console: "%d{HH:mm:ss} ${LOG_LEVEL_PATTERN:-%5p} %m%n"
spring.cloud.kubernetes.discovery.all-namespaces: true
spring:
data:
mongodb:
database: admin
host: mongodb.default
In config map we define Mongo location, logs pattern and property responsible for allowing multi-namespace discovery. Mongo credentials should be defined inside Secret object. The rules are the same as for config maps.
apiVersion: v1
kind: Secret
metadata:
name: employee
type: Opaque
data:
spring.data.mongodb.username: UGlvdF8xMjM=
spring.data.mongodb.password: cGlvdHI=
It is worth to note that by default, consuming secrets through the API is not enabled for security reasons. However, we have already set default cluster-admin role, so we don’t have to worry about it. The only thing we have to do is to enable consuming secrets through API for Spring Cloud Kubernetes, which is disabled by default. To do that we have to use set the following property in bootstrap.yml.
spring:
cloud:
kubernetes:
secrets:
enableApi: true
Deploying Spring Cloud apps on Minikube
First, let’s create required namespaces using kubectl create namespace command. Here are the commands that create namespaces a, b, c and d.

Then, let’s build the code by executing Maven mvn clean install command.

We also need to set cluster-admin for newly created namespaces in order to allow pods running inside these namespaces to read master API.


Now, let’s take a look on our Kubernetes deployment manifest. It is very simple, since it does not inject any properties from ConfigMap and Secret. It is already performed by Spring Cloud Kubernetes Config. Here’s a deployment YAML file for employee-service.
apiVersion: apps/v1
kind: Deployment
metadata:
name: employee
labels:
app: employee
spec:
replicas: 1
selector:
matchLabels:
app: employee
template:
metadata:
labels:
app: employee
spec:
containers:
- name: employee
image: piomin/employee:1.1
ports:
- containerPort: 8080
Finally, we may deploy our applications on Kubernetes. Each microservice has ConfigMap, Secret, Deployment and Service objects. The YAML manifest is available in the Git repository inside /kubernetes directory. We are applying them sequentially using kubectl apply command as shown below.
For the test purposes you may expose the sample application outside a node by defining NodePort type.
apiVersion: v1
kind: Service
metadata:
name: department
labels:
app: department
spec:
ports:
- port: 8080
protocol: TCP
selector:
app: department
type: NodePort
Exposing info about a pod
If you defined your Service as NodePort you can easily access it outside Minikube. To retrieve a target port just execute kubectl get svc as shown below. Now, you would be able to call it using address http://192.168.99.100:31119.


With Spring Cloud Kubernetes each Spring Boot application exposes information about pod ip, pod name and namespace name. To enter it you need to call /info endpoint as shown below.
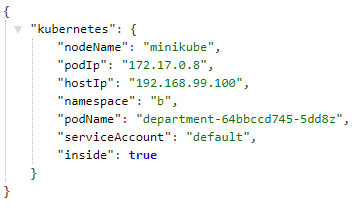

Here’s the list of pods distributed between all namespaces after deploying all sample microservices and gateway.
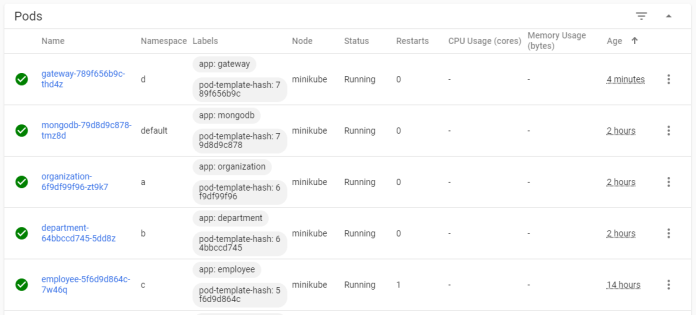

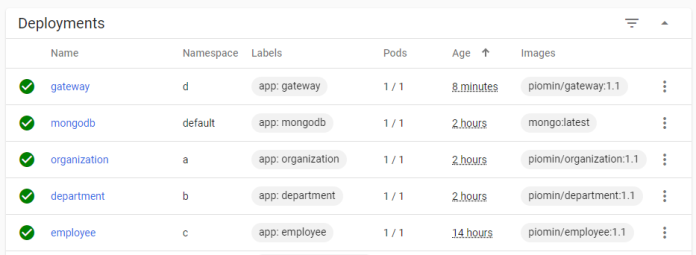
And also a list of deployments.

Running gateway
The last element in our architecture is the gateway. We use Spring Cloud Netflix Zuul, which is integrated with Kubernetes discovery via Ribbon client. It is exposing Swagger documentation for all our sample microservices distributed across multiple namespaces. Here’s a list of required dependencies.
<dependencies>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-netflix-zuul</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-kubernetes-all</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-sleuth</artifactId>
</dependency>
<dependency>
<groupId>io.springfox</groupId>
<artifactId>springfox-swagger-ui</artifactId>
<version>2.9.2</version>
</dependency>
<dependency>
<groupId>io.springfox</groupId>
<artifactId>springfox-swagger2</artifactId>
<version>2.9.2</version>
</dependency>
</dependencies>
The configuration of routes is pretty simple. We just need to use the Spring Cloud Kubernetes discovery feature.
apiVersion: v1
kind: ConfigMap
metadata:
name: gateway
data:
logging.pattern.console: "%d{HH:mm:ss} ${LOG_LEVEL_PATTERN:-%5p} %m%n"
spring.cloud.kubernetes.discovery.all-namespaces: "true"
zuul.routes.department.path: "/department/**"
zuul.routes.employee.path: "/employee/**"
zuul.routes.organization.path: "/organization/**"
While Zuul proxy is automatically integrated with DiscoveryClient we may easily configure dynamic resolution Swagger endpoints exposed by microservices.
@Configuration
public class GatewayApi {
@Autowired
ZuulProperties properties;
@Primary
@Bean
public SwaggerResourcesProvider swaggerResourcesProvider() {
return () -> {
List<SwaggerResource> resources = new ArrayList<>();
properties.getRoutes().values().stream()
.forEach(route -> resources.add(createResource(route.getId(), "2.0")));
return resources;
};
}
private SwaggerResource createResource(String location, String version) {
SwaggerResource swaggerResource = new SwaggerResource();
swaggerResource.setName(location);
swaggerResource.setLocation("/" + location + "/v2/api-docs");
swaggerResource.setSwaggerVersion(version);
return swaggerResource;
}
}
Normally, we would have to configure Kubernetes Ingress in order to access gateway. With Minikube we just have to create a service with type NodePort. Finally, we may start testing our applications using the Swagger UI exposed on the gateway. But here, we get an unexpected surprise… The discovery across all namespaces does not work for the Ribbon client. It only works for DiscoveryClient. I think that Ribbon auto-configuration should respect the property spring.cloud.kubernetes.discovery.all-namespaces, but in that case we don’t have any other choice than prepare a workaround. Our workaround is to override Ribbon client auto-configuration provided within Spring Cloud Kubernetes. We are using DiscoveryClient directly for it as shown below.
public class RibbonConfiguration {
@Autowired
private DiscoveryClient discoveryClient;
private String serviceId = "client";
protected static final String VALUE_NOT_SET = "__not__set__";
protected static final String DEFAULT_NAMESPACE = "ribbon";
public RibbonConfiguration () {
}
public RibbonConfiguration (String serviceId) {
this.serviceId = serviceId;
}
@Bean
@ConditionalOnMissingBean
public ServerList<?> ribbonServerList(IClientConfig config) {
Server[] servers = discoveryClient.getInstances(config.getClientName()).stream()
.map(i -> new Server(i.getHost(), i.getPort()))
.toArray(Server[]::new);
return new StaticServerList(servers);
}
}
The Ribbon configuration class needs to be set on the main class.
@SpringBootApplication
@EnableDiscoveryClient
@EnableZuulProxy
@EnableSwagger2
@AutoConfigureAfter(RibbonAutoConfiguration.class)
@RibbonClients(defaultConfiguration = RibbonConfiguration.class)
public class GatewayApplication {
public static void main(String[] args) {
SpringApplication.run(GatewayApplication.class, args);
}
}
Now, we can finally take advantage of multi namespace discovery and load balancing and easily test it using the Swagger UI exposed on the gateway.
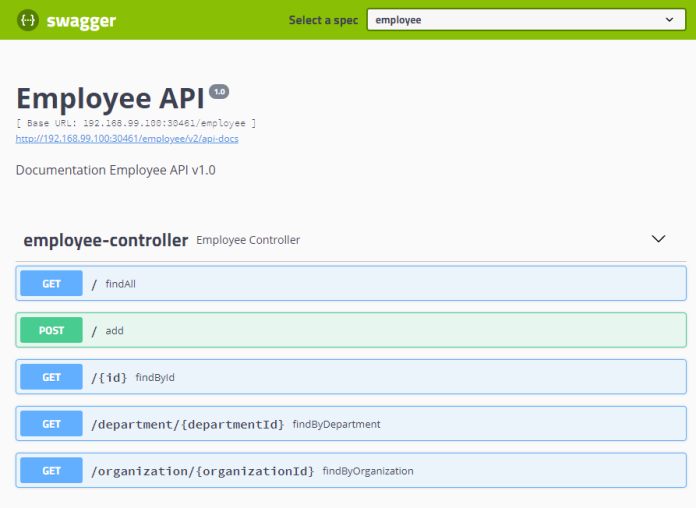

Summary
Spring Cloud Kubernetes is currently one of the most popular Spring Cloud projects. In this context, it may be a little surprising that it is not up-to-date with the latest Spring Cloud features. For example, it still uses Ribbon instead of the new Spring Cloud Load Balancer. Anyway, it provides some useful mechanisms that simplifies Spring Boot application deployment on Kubernetes. In this article I presented the most useful features like discovery across all namespaces or configuration property sources with Kubernetes ConfigMap and Secret.


















31 COMMENTS