RabbitMQ in cluster
RabbitMQ grown into the most popular message broker software. It is written in Erlang and implements Advanced Message Queueing Protocol (AMQP). It is easy to use and configure even if we are talking about such mechanisms as clustering or high availability. In this post, I’m going to show you how to run some instances of RabbitMQ provided in docker containers in the cluster with highly available (HA) queues. Based on the sample Java application we’ll see how to send and receive messages from the RabbitMQ cluster and check how this message broker handles a large number of incoming messages. Sample Spring Boot application is available on GitHub. Here is a picture illustrating the architecture of our solution.
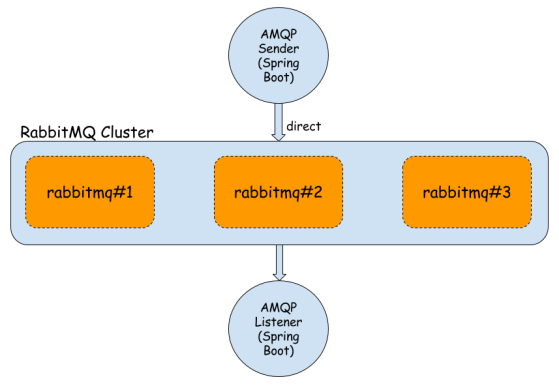

We use an official Docker repository of RabbitMQ. Here are commands for running three RabbitMQ nodes. The first node is the master of the cluster – two other nodes will join him. We use container management to enable an UI administration console for each node. Every node has a default connection and UI management ports exposed. Important thing is to link rabbit2 and rabbit3 constainers to rabbit1, which is necessary while joining to cluster mastering by rabbit1.
$ docker run -d --hostname rabbit1 --name rabbit1 -e RABBITMQ_ERLANG_COOKIE='rabbitcluster' -p 30000:5672 -p 30001:15672 rabbitmq:management
$ docker run -d --hostname rabbit2 --name rabbit2 --link rabbit1:rabbit1 -e RABBITMQ_ERLANG_COOKIE='rabbitcluster' -p 30002:5672 -p 30003:15672 rabbitmq:management
$ docker run -d --hostname rabbit3 --name rabbit3 --link rabbit1:rabbit1 -e RABBITMQ_ERLANG_COOKIE='rabbitcluster' -p 30004:5672 -p 30005:15672 rabbitmq:management
Ok, now there are three RabbitMQ running instances. We can go to the UI management console for all of those instances available as docker containers, for example http://192.168.99.100:30001 (rabbitmq). Each instance is available on its independent cluster like we see in the pictures below. We would like to make all instances working in the same cluster rabbit@rabbit1.




Here’s set of commands run on rabbit2 instance for joining cluster rabbit@rabbit1. The same set should be run on rabbit3 node. In the beginning we have to connect to docker container and run bash command. Before running rabbitmq join_cluster command we have to stop broker.
$ docker exec -i -t rabbit2 \bash
root@rabbit2:/# rabbitmqctl stop_app
Stopping node rabbit@rabbit2 ...
root@rabbit2:/# rabbitmqctl join_cluster rabbit@rabbit1
Clustering node rabbit@rabbit2 with rabbit@rabbit1 ...
root@rabbit2:/# rabbitmqctl start_app
Starting node rabbit@rabbit2 ...
If everything was successful we should see cluster name rabbit@rabbit1 in upper right corner of rabbit2 management console. You should also see list of running nodes in the Nodes section. You can also check cluster status by running on every node command rabbitmqctl cluster_status, which should also display list of all cluster nodes.


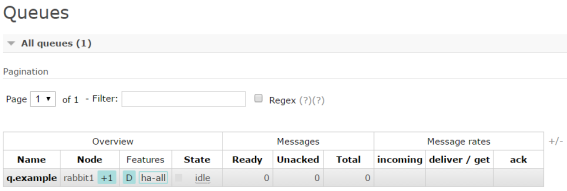
After starting all nodes go to UI managent console on one of nodes. Now we are going to configure High Availibility for selected queue. It is not important which node you choose, because they are in one cluster. In the Queues tab create queue with name q.example. Then go to Admin tab and select Policies section and create new policy. In the picture below you can see policy I have created. I selected ha-mode=all which means that is mirrored across all nodes in the cluster and when a new node is added to the cluster, the queue will be mirrored to that node. There are also available exactly, nodes modes – more about RabbitMQ high availability you can find here. In pattern field enter your queue name and in apply to select Queues. If everything was succeeded you should see ha-all feature in queue row.

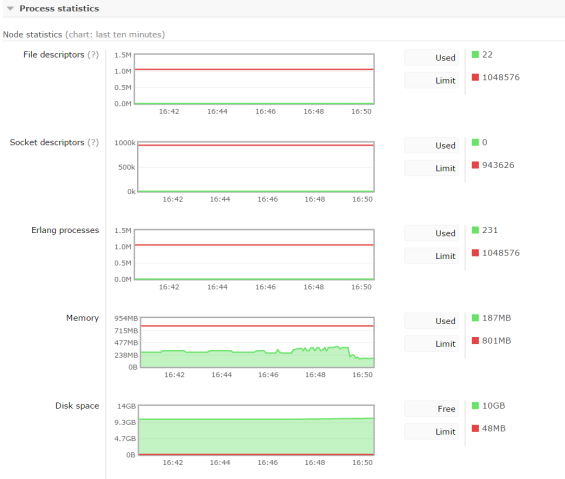
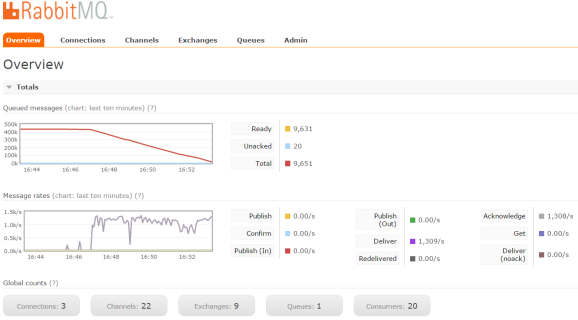
One of the greatest advantages of RabbitMQ is monitoring. You can see many statistics like memory, disk usage, I/O statistics, detailed message rates, graphs, etc. Some of them you could see below.


RabbitMQ has great support in the Spring framework. There many projects in which use RabbitMQ implementation by default, for example, Spring Cloud Stream, Spring Cloud Sleuth. I’m going to show you a sample Spring Boot application that sends messages to RabbitMQ cluster and receives them from the HA queue. The application source code is available on GitHub. Here’s the main class of application. We enable RabbitMQ listener by declaring @EnableRabbit on class and @RabbitListener on the receiving method. We also have to declare listened queue, broker connection factory, and listener container factory to allow listener concurrency. Inside CachingConnectionFactory we set all three addresses of RabbitMQ cluster instances: 192.168.99.100:30000, 192.168.99.100:30002, 192.168.99.100:30004.
@SpringBootApplication
@EnableRabbit
public class Listener {
private static Logger logger = Logger.getLogger("Listener");
public static void main(String[] args) {
SpringApplication.run(Listener.class, args);
}
@RabbitListener(queues = "q.example")
public void onMessage(Order order) {
logger.info(order.toString());
}
@Bean
public ConnectionFactory connectionFactory() {
CachingConnectionFactory connectionFactory = new CachingConnectionFactory();
connectionFactory.setUsername("guest");
connectionFactory.setPassword("guest");
connectionFactory.setAddresses("192.168.99.100:30000,192.168.99.100:30002,192.168.99.100:30004");
connectionFactory.setChannelCacheSize(10);
return connectionFactory;
}
@Bean
public SimpleRabbitListenerContainerFactory rabbitListenerContainerFactory() {
SimpleRabbitListenerContainerFactory factory = new SimpleRabbitListenerContainerFactory();
factory.setConnectionFactory(connectionFactory());
factory.setConcurrentConsumers(10);
factory.setMaxConcurrentConsumers(20);
return factory;
}
@Bean
public Queue queue() {
return new Queue("q.example");
}
}
Conclusion
Clustering and high availability configuration with RabbitMQ is pretty simple. I like Rabbit MQ for support in the cluster monitoring process with UI management console. In my opinion, it is user friendly and intuitive. In the sample application, I send 100k messages into the sample queue. Using 20 concurrent consumers they were processed 65 seconds (~80/s per consumer thread) and memory usage at its peak was about 400MB on each node. Of course, our application is just receiving an object message and logging it in the console.










10 COMMENTS