Spring Boot Autoscaler
One of more important reasons we are deciding to use such tools like Kubernetes, Pivotal Cloud Foundry or HashiCorp’s Nomad is the availability of auto-scaling our applications. Of course those tools provide many other useful mechanisms, but we can implement auto-scaling by ourselves. At first glance it seems to be difficult, but assuming we use Spring Boot as a framework for building our applications and Jenkins as a CI server, it finally does not require a lot of work.
Today, I’m going to show you how to implement such a solutions using the following frameworks/tools:
- Spring Boot
- Spring Boot Actuator
- Spring Cloud Netflix Eureka
- Jenkins CI
How it works?
Every Spring Boot application, which contains Spring Boot Actuator library can expose metrics under endpoint /actuator/metrics. There are many valuable metrics that give you the detailed information about an application status. Some of them may be especially important when talking about Spring Boot microservices autoscaling: JVM, CPU metrics, a number of running threads and a number of incoming HTTP requests. There is a dedicated Jenkins pipeline responsible for monitoring application’s metrics by polling endpoint /actuator/metrics periodically. If any monitored metrics is below or above target range it runs a new instance or shutdown a running instance of application using another Actuator endpoint /actuator/shutdown. Before that, it needs to fetch the current list of running instances of a single application in order to get an address of an existing application selected for shutting down or the address of the server with the smallest number of running instances for a new instance of application..
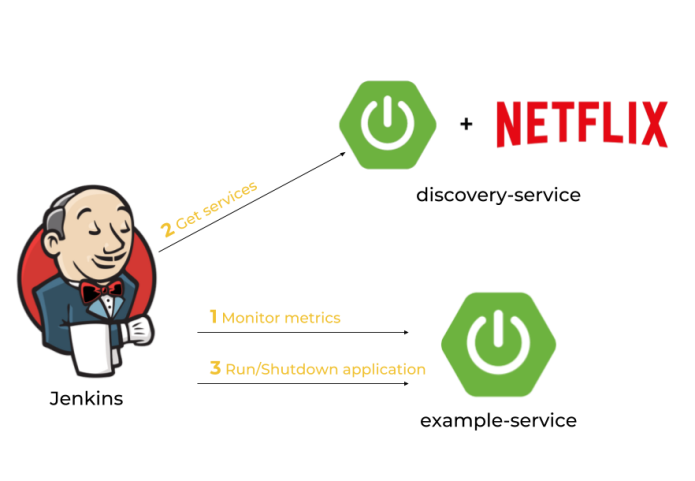
After discussing the architecture of our system we may proceed to the development. Our application needs to meet some requirements: it has to expose metrics and endpoints for graceful shutdown, it needs to register in Eureka after after startup and deregister on shutdown, and finally it also should dynamically allocate a running port randomly from the pool of free ports. Thanks to Spring Boot we may easily implement all these mechanisms in five minutes 🙂
Dynamic port allocation
Since it is possible to run many instances of application on a single machine we have to guarantee that there won’t be conflicts in port numbers. Fortunately, Spring Boot provides such mechanisms for an application. We just need to set port number to 0 inside application.yml file using server.port property. Because our application registers itself in eureka it also needs to send unique instanceId, which is by default generated as a concatenation of fields spring.cloud.client.hostname, spring.application.name and server.port.
Here’s the current configuration of our sample application. I have changed the template of instanceId field by replacing number of port to randomly generated number.
spring:
application:
name: example-service
server:
port: ${PORT:0}
eureka:
instance:
instanceId: ${spring.cloud.client.hostname}:${spring.application.name}:${random.int[1,999999]}
Enabling Actuator metrics
To enable Spring Boot Actuator we need to include the following dependency to pom.xml.
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-actuator</artifactId>
</dependency>
We also have to enable exposure of actuator endpoints via HTTP API by setting property management.endpoints.web.exposure.include to '*'. Now, the list of all available metric names is available under context path /actuator/metrics, while detailed information for each metric under path /actuator/metrics/{metricName}.
Graceful shutdown
Besides metrics Spring Boot Actuator also provides an endpoint for shutting down an application. However, in contrast to other endpoints this endpoint is not available by default. We have to set property management.endpoint.shutdown.enabled to true. After that we will have to stop our application by sending the POST request to /actuator/shutdown endpoint.
This method of stopping application guarantees that service will unregister itself from the Eureka server before shutdown.
Enabling Eureka discovery
Eureka is the most popular discovery server used for building microservices-based architecture with Spring Cloud. So, if you already have microservices and want to provide auto-scaling mechanisms for them, Eureka would be a natural choice. It contains the IP address and port number of every registered instance of application. To enable Eureka on the client side you just need to include the following dependency to your pom.xml.
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-netflix-eureka-client</artifactId>
</dependency>
As I have mentioned before we also have to guarantee a uniqueness of instanceId send to Eureka server by the client-side application. It has been described in the step
The next step is to create an application with an embedded Eureka server. To achieve it we first need to include the following dependency into pom.xml.
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-netflix-eureka-server</artifactId>
</dependency>
The main class should be annotated with @EnableEurekaServer.
@SpringBootApplication
@EnableEurekaServer
public class DiscoveryApp {
public static void main(String[] args) {
new SpringApplicationBuilder(DiscoveryApp.class).run(args);
}
}
Client-side applications by default try to connect with the Eureka server on localhost under port 8761. We only need a single, standalone Eureka node, so we will disable registration and attempts to fetch a list of services from other instances of the server.
spring:
application:
name: discovery-service
server:
port: ${PORT:8761}
eureka:
instance:
hostname: localhost
client:
registerWithEureka: false
fetchRegistry: false
serviceUrl:
defaultZone: http://localhost:8761/eureka/
The tests of the sample Spring Boot microservices autoscaling system will be performed using Docker containers, so we need to prepare and build images with the Eureka server. Here’s Dockerfile with image definition. It can be built using command docker build -t piomin/discovery-server:2.0 ..
FROM openjdk:8-jre-alpine
ENV APP_FILE discovery-service-1.0-SNAPSHOT.jar
ENV APP_HOME /usr/apps
EXPOSE 8761
COPY target/$APP_FILE $APP_HOME/
WORKDIR $APP_HOME
ENTRYPOINT ["sh", "-c"]
CMD ["exec java -jar $APP_FILE"]
Building Jenkins pipeline for autoscaling
The first step is to prepare the Jenkins pipeline responsible for autoscaling. We will create the Jenkins Declarative Pipeline, which runs every minute. Periodical execution may be configured with the triggers directive, that defines the automated ways in which the pipeline should be re-triggered. Our pipeline will communicate with Eureka server and metrics endpoints exposed by every microservice using Spring Boot Actuator.
The test service name is EXAMPLE-SERVICE, which is equal to value (big letters) of property spring.application.name defined inside application.yml file. The monitored metric is the number of HTTP listener threads running on a Tomcat container. These threads are responsible for processing incoming HTTP requests.
pipeline {
agent any
triggers {
cron('* * * * *')
}
environment {
SERVICE_NAME = "EXAMPLE-SERVICE"
METRICS_ENDPOINT = "/actuator/metrics/tomcat.threads.busy?tag=name:http-nio-auto-1"
SHUTDOWN_ENDPOINT = "/actuator/shutdown"
}
stages { ... }
}
Integrating Jenkins pipeline with Eureka
The first stage of our pipeline is responsible for fetching a list of services registered in the service discovery server. Eureka exposes HTTP API with several endpoints. One of them is GET /eureka/apps/{serviceName}, which returns a list of all instances of an application with a given name. We are saving the number of running instances and the URL of metrics endpoint of every single instance. These values would be accessed during next stages of the pipeline.
Here’s the fragment pipeline responsible for fetching a list of running instances of the application. The name of stage is Calculate. We use HTTP Request Plugin for HTTP connections.
stage('Calculate') {
steps {
script {
def response = httpRequest "http://192.168.99.100:8761/eureka/apps/${env.SERVICE_NAME}"
def app = printXml(response.content)
def index = 0
env["INSTANCE_COUNT"] = app.instance.size()
app.instance.each {
if (it.status == 'UP') {
def address = "http://${it.ipAddr}:${it.port}"
env["INSTANCE_${index++}"] = address
}
}
}
}
}
@NonCPS
def printXml(String text) {
return new XmlSlurper(false, false).parseText(text)
}
Here’s a sample response from Eureka API for our microservice. The response content type is XML.

Integrating Jenkins pipeline with Spring Boot Actuator metrics
Spring Boot Actuator exposes an endpoint with metrics, which allows to find metrics by name and optionally by tag. In the fragment of pipeline visible below I’m trying to find the instance with a metric below or above a defined threshold. If there is such an instance we stop the loop in order to proceed to the next stage, which performs scaling down or up. The ip addresses of running applications are taken from the pipeline environment variable with prefix INSTANCE_, which has been saved in the previous stage.
stage('Metrics') {
steps {
script {
def count = env.INSTANCE_COUNT
for(def i=0; i<count; i++) {
def ip = env["INSTANCE_${i}"] + env.METRICS_ENDPOINT
if (ip == null)
break;
def response = httpRequest ip
def objRes = printJson(response.content)
env.SCALE_TYPE = returnScaleType(objRes)
if (env.SCALE_TYPE != "NONE")
break
}
}
}
}
@NonCPS
def printJson(String text) {
return new JsonSlurper().parseText(text)
}
def returnScaleType(objRes) {
def value = objRes.measurements[0].value
if (value.toInteger() > 100)
return "UP"
else if (value.toInteger() < 20)
return "DOWN"
else
return "NONE"
}
Shutdown application instance
In the last stage of our pipeline we will shutdown the running instance or start a new instance depending on the result saved in the previous stage. Shutdown may be easily performed by calling Spring Boot Actuator endpoint. In the following fragment of pipeline we pick the instance returned by Eureka as first. Then we send POST requests to that ip address.
If we need to scale up our application we call another pipeline responsible for building a fat JAR and launch it on our machine.
stage('Scaling') {
steps {
script {
if (env.SCALE_TYPE == 'DOWN') {
def ip = env["INSTANCE_0"] + env.SHUTDOWN_ENDPOINT
httpRequest url:ip, contentType:'APPLICATION_JSON', httpMode:'POST'
} else if (env.SCALE_TYPE == 'UP') {
build job:'spring-boot-run-pipeline'
}
currentBuild.description = env.SCALE_TYPE
}
}
}
Here’s a full definition of our pipeline spring-boot-run-pipeline responsible for starting a new instance of application. It clones the repository with application source code, builds binaries using Maven commands, and finally runs the application using java -jar command passing the address of Eureka server as a parameter.
pipeline {
agent any
tools {
maven 'M3'
}
stages {
stage('Checkout') {
steps {
git url: 'https://github.com/piomin/sample-spring-boot-autoscaler.git', credentialsId: 'github-piomin', branch: 'master'
}
}
stage('Build') {
steps {
dir('example-service') {
sh 'mvn clean package'
}
}
}
stage('Run') {
steps {
dir('example-service') {
sh 'nohup java -jar -DEUREKA_URL=http://192.168.99.100:8761/eureka target/example-service-1.0-SNAPSHOT.jar 1>/dev/null 2>logs/runlog &'
}
}
}
}
}
Remote extension
The algorithm discussed in the previous sections will work fine only for microservices launched on the single machine. If we would like to extend it to work with many machines, we will have to modify our architecture as shown below. Each machine has a Jenkins agent running and communicating with Jenkins master. If we would like to start a new instance of microservices on the selected machine, we have to run a pipeline using an agent running on that machine. This agent is responsible only for building applications from source code and launching it on the target machine. The shutdown of instance is still performed just by calling HTTP endpoint.
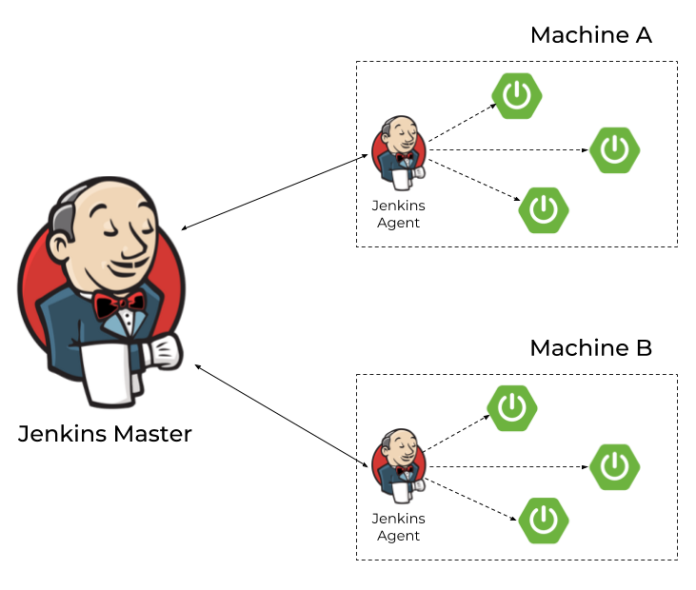
You can find more information about running Jenkins agents and connecting them with Jenkins master via JNLP protocol in my article Jenkins nodes on Docker containers. Assuming we have successfully launched some agents on the target machines we need to parametrize our pipelines in order to be able to select agents (and therefore the target machine) dynamically.
When we are scaling up our application we have to pass the agent label to the downstream pipeline.
build job:'spring-boot-run-pipeline', parameters:[string(name: 'agent', value:"slave-1")]
The calling pipeline will be run by an agent labelled with a given parameter.
pipeline {
agent {
label "${params.agent}"
}
stages { ... }
}
If we have more than one agent connected to the master node we can map their addresses into the labels. Thanks to that you would be able to map the IP address of the microservice instance fetched from Eureka to the target machine with Jenkins agent.
pipeline {
agent any
triggers {
cron('* * * * *')
}
environment {
SERVICE_NAME = "EXAMPLE-SERVICE"
METRICS_ENDPOINT = "/actuator/metrics/tomcat.threads.busy?tag=name:http-nio-auto-1"
SHUTDOWN_ENDPOINT = "/actuator/shutdown"
AGENT_192.168.99.102 = "slave-1"
AGENT_192.168.99.103 = "slave-2"
}
stages { ... }
}
Summary
In this article, I have demonstrated how to use Spring Boot Actuator metrics in order to scale up/scale down your Spring Boot application. Using basic mechanisms provided by Spring Boot together with Spring Cloud Netflix Eureka and Jenkins you can implement Spring Boot microservices autoscaling for your applications without getting any other third-party tools. The case described in this article assumes using Jenkins agents on the remote machines to launch their new instance of the application, but you may as well use a tool like Ansible for that. If you would decide to run Ansible playbooks from Jenkins you will not have to launch Jenkins agents on remote machines. The source code with sample applications is available on GitHub: https://github.com/piomin/sample-spring-boot-autoscaler.git.

2 COMMENTS