An Advanced Guide to GraphQL with Spring Boot
In this guide I’m going to discuss some more advanced topics related to GraphQL and databases, like filtering or relationship fetching. Of course, before proceeding to the more advanced issues I will take a moment to describe the basics – something you can be found in many other articles. If you already had the opportunity to familiarize yourself with the concept over GraphQL you may have some questions. Probably one of them is: “Ok. It’s nice. But what if I would like to use GraphQL in the real application that connects to the database and provides API for more advanced queries?”.
If that is your main question, my current article is definitely for you. If you are thinking about using GraphQL in your microservices architecture you may also refer to my previous article GraphQL – The Future of Microservices?.
Example
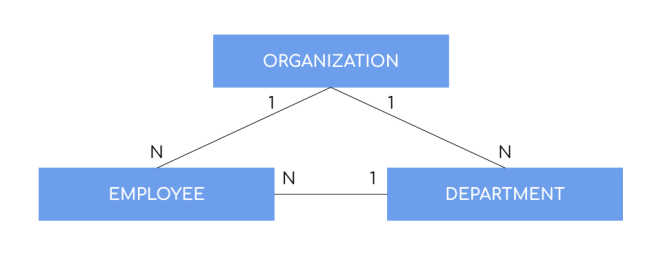
As you know it is best to learn from examples, so I have created a sample Spring Boot application that exposes API using GraphQL and connects to H2 in-memory database. We will discuss Spring Boot GraphQL JPA support. For integration with the H2 database I’m using Spring Data JPA and Hibernate. I have implemented three entities Employee, Department and Organization – each of them stored in the separated table. A relationship model between them has been visualized in the picture below.
A source code with sample application is available on GitHub in repository: https://github.com/piomin/sample-spring-boot-graphql.git
1. Dependencies
Let’s start from dependencies. Here’s a list of required dependencies for our application. We need to include projects Spring Web, Spring Data JPA and com.database:h2 artifact for embedding in-memory database to our application. I’m also using Spring Boot library offering support for GraphQL. In fact, you may find some other Spring Boot GraphQL JPA libraries, but the one under group com.graphql-java-kickstart (https://www.graphql-java-kickstart.com/spring-boot/) seems to be actively developed and maintained.
<properties>
<graphql.spring.version>7.1.0</graphql.spring.version>
</properties>
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-jpa</artifactId>
</dependency>
<dependency>
<groupId>com.h2database</groupId>
<artifactId>h2</artifactId>
<scope>runtime</scope>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
</dependency>
<dependency>
<groupId>com.graphql-java-kickstart</groupId>
<artifactId>graphql-spring-boot-starter</artifactId>
<version>${graphql.spring.version}</version>
</dependency>
<dependency>
<groupId>com.graphql-java-kickstart</groupId>
<artifactId>graphiql-spring-boot-starter</artifactId>
<version>${graphql.spring.version}</version>
</dependency>
<dependency>
<groupId>com.graphql-java-kickstart</groupId>
<artifactId>graphql-spring-boot-starter-test</artifactId>
<version>${graphql.spring.version}</version>
<scope>test</scope>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
</dependencies>
2. Schemas
We are starting implementation from defining GraphQL schemas with objects, queries and mutations definitions. The files are located inside /src/main/resources/graphql directory and after adding graphql-spring-boot-starter they are automatically detected by the application basing on their suffix *.graphqls.
GraphQL schema for each entity is located in the separated file. Let’s take a look on department.graphqls. It’s a very trivial definition.
type QueryResolver {
departments: [Department]
department(id: ID!): Department!
}
type MutationResolver {
newDepartment(department: DepartmentInput!): Department
}
input DepartmentInput {
name: String!
organizationId: Int
}
type Department {
id: ID!
name: String!
organization: Organization
employees: [Employee]
}
Here’s the schema inside file organization.graphqls. As you see I’m using keyword extend on QueryResolver and MutationResolver.
extend type QueryResolver {
organizations: [Organization]
organization(id: ID!): Organization!
}
extend type MutationResolver {
newOrganization(organization: OrganizationInput!): Organization
}
input OrganizationInput {
name: String!
}
type Organization {
id: ID!
name: String!
employees: [Employee]
departments: [Department]
}
Schema for Employee is a little bit more complicated than two previously demonstrated schemas. I have defined an input object for filtering. It will be discussed in the next section in detail.
extend type QueryResolver {
employees: [Employee]
employeesWithFilter(filter: EmployeeFilter): [Employee]
employee(id: ID!): Employee!
}
extend type MutationResolver {
newEmployee(employee: EmployeeInput!): Employee
}
input EmployeeInput {
firstName: String!
lastName: String!
position: String!
salary: Int
age: Int
organizationId: Int!
departmentId: Int!
}
type Employee {
id: ID!
firstName: String!
lastName: String!
position: String!
salary: Int
age: Int
department: Department
organization: Organization
}
input EmployeeFilter {
salary: FilterField
age: FilterField
position: FilterField
}
input FilterField {
operator: String!
value: String!
}
schema {
query: QueryResolver
mutation: MutationResolver
}
3. Domain model
Let’s take a look at the corresponding domain model. Here’s Employee entity. Each Employee is assigned to a single Department and Organization.
@Entity
@Data
@NoArgsConstructor
@AllArgsConstructor
@EqualsAndHashCode(onlyExplicitlyIncluded = true)
public class Employee {
@Id
@GeneratedValue
@EqualsAndHashCode.Include
private Integer id;
private String firstName;
private String lastName;
private String position;
private int salary;
private int age;
@ManyToOne(fetch = FetchType.LAZY)
private Department department;
@ManyToOne(fetch = FetchType.LAZY)
private Organization organization;
}
Here’s Department entity. It contains a list of employees and a reference to a single organization.
@Entity
@Data
@AllArgsConstructor
@NoArgsConstructor
@EqualsAndHashCode(onlyExplicitlyIncluded = true)
public class Department {
@Id
@GeneratedValue
@EqualsAndHashCode.Include
private Integer id;
private String name;
@OneToMany(mappedBy = "department")
private Set<Employee> employees;
@ManyToOne(fetch = FetchType.LAZY)
private Organization organization;
}
And finally Organization entity.
@Entity
@Data
@AllArgsConstructor
@NoArgsConstructor
@EqualsAndHashCode(onlyExplicitlyIncluded = true)
public class Organization {
@Id
@GeneratedValue
@EqualsAndHashCode.Include
private Integer id;
private String name;
@OneToMany(mappedBy = "organization")
private Set<Department> departments;
@OneToMany(mappedBy = "organization")
private Set<Employee> employees;
}
Entity classes are returned as a result by queries. In mutations we are using input objects that have slightly different implementation. They do not contain reference to a relationship, but only an id of related objects.
@Data
@AllArgsConstructor
@NoArgsConstructor
public class DepartmentInput {
private String name;
private Integer organizationId;
}
4. Fetch relations
As you probably figured out, all the JPA relations are configured in lazy mode. To fetch them we should explicitly set such a request in our GraphQL query. For example, we may query all departments and fetch organization to each of the department returned on the list.
{
departments {
id
name
organization {
id
name
}
}
}
Now, the question is how to handle it on the server side. The first thing we need to do is to detect the existence of such a relationship field in our GraphQL query. Why? Because we need to avoid possible N+1 problem, which happens when the data access framework executes N additional SQL statements to fetch the same data that could have been retrieved when executing the primary SQL query. So, we need to prepare different JPA queries depending on the parameters set in the GraphQL query. We may do it in several ways, but the most convenient way is by using DataFetchingEnvironment parameter inside QueryResolver implementation.
Let’s take a look on the implementation of QueryResolver for Department. If we annotate class that implements GraphQLQueryResolver with @Component it is automatically detected by Spring Boot (thanks to graphql-spring-boot-starter). Then we are adding DataFetchingEnvironment as a parameter to each query. After that we should invoke method getSelectionSet() on DataFetchingEnvironment object and check if it contains word organization (for fetching Organization) or employees (for fetching list of employees). Depending on requested relations we build different queries. In the following fragment of code we have two methods implemented for DepartmentQueryResolver: findAll and findById.
@Component
public class DepartmentQueryResolver implements GraphQLQueryResolver {
private DepartmentRepository repository;
DepartmentQueryResolver(DepartmentRepository repository) {
this.repository = repository;
}
public Iterable<Department> departments(DataFetchingEnvironment environment) {
DataFetchingFieldSelectionSet s = environment.getSelectionSet();
List<Specification<Department>> specifications = new ArrayList<>();
if (s.contains("employees") && !s.contains("organization"))
return repository.findAll(fetchEmployees());
else if (!s.contains("employees") && s.contains("organization"))
return repository.findAll(fetchOrganization());
else if (s.contains("employees") && s.contains("organization"))
return repository.findAll(fetchEmployees().and(fetchOrganization()));
else
return repository.findAll();
}
public Department department(Integer id, DataFetchingEnvironment environment) {
Specification<Department> spec = byId(id);
DataFetchingFieldSelectionSet selectionSet = environment.getSelectionSet();
if (selectionSet.contains("employees"))
spec = spec.and(fetchEmployees());
if (selectionSet.contains("organization"))
spec = spec.and(fetchOrganization());
return repository.findOne(spec).orElseThrow(NoSuchElementException::new);
}
// REST OF IMPLEMENTATION ...
}
The most convenient way to build dynamic queries is by using JPA Criteria API. To be able to use it with Spring Data JPA we first need to extend our repository interface with JpaSpecificationExecutor interface. After that you may use the additional interface methods that let you execute specifications in a variety of ways. You may choose between findAll and findOne methods.
public interface DepartmentRepository extends CrudRepository<Department, Integer>,
JpaSpecificationExecutor<Department> {
}
Finally, we may just prepare methods that build Specification the object. This object contains a predicate. In that case we are using three predicates for fetching organization, employees and filtering by id.
private Specification<Department> fetchOrganization() {
return (Specification<Department>) (root, query, builder) -> {
Fetch<Department, Organization> f = root.fetch("organization", JoinType.LEFT);
Join<Department, Organization> join = (Join<Department, Organization>) f;
return join.getOn();
};
}
private Specification<Department> fetchEmployees() {
return (Specification<Department>) (root, query, builder) -> {
Fetch<Department, Employee> f = root.fetch("employees", JoinType.LEFT);
Join<Department, Employee> join = (Join<Department, Employee>) f;
return join.getOn();
};
}
private Specification<Department> byId(Integer id) {
return (Specification<Department>) (root, query, builder) -> builder.equal(root.get("id"), id);
}
5. Filtering
For a start, let’s refer to the section 2 – Schemas. Inside employee.graphqls I defined two additional inputs FilterField and EmployeeFilter, and also a single method employeesWithFilter that takes EmployeeFilter as an argument. The FieldFilter class is my custom implementation of a filter for GraphQL queries. It is very trivial. It provides an implementation of two filter types: for number or for string. It generates JPA Criteria Predicate. Of course, instead creating such filter implementation by yourself (like me), you may leverage some existing libraries for that. However, it does not require much time to do it by yourself as you see in the following code. Our custom filter implementation has two parameters: operator and value.
@Data
public class FilterField {
private String operator;
private String value;
public Predicate generateCriteria(CriteriaBuilder builder, Path field) {
try {
int v = Integer.parseInt(value);
switch (operator) {
case "lt": return builder.lt(field, v);
case "le": return builder.le(field, v);
case "gt": return builder.gt(field, v);
case "ge": return builder.ge(field, v);
case "eq": return builder.equal(field, v);
}
} catch (NumberFormatException e) {
switch (operator) {
case "endsWith": return builder.like(field, "%" + value);
case "startsWith": return builder.like(field, value + "%");
case "contains": return builder.like(field, "%" + value + "%");
case "eq": return builder.equal(field, value);
}
}
return null;
}
}
Now, with FilterField we may create a concrete implementation of filters consisting of several simple FilterField. The example of such implementation is EmployeeFilter class that has three possible criterias of filtering by salary, age and position.
@Data
public class EmployeeFilter {
private FilterField salary;
private FilterField age;
private FilterField position;
}
Now if you would like to use that filter in your GraphQL query you should create something like that. In that query we are searching for all developers that has a salary greater than 12000 and age greater than 30 years.
{
employeesWithFilter(filter: {
salary: {
operator: "gt"
value: "12000"
},
age: {
operator: "gt"
value: "30"
},
position: {
operator: "eq",
value: "Developer"
}
}) {
id
firstName
lastName
position
}
}
Let’s take a look at the implementation of query resolver. The same as for fetching relations we are using JPA Criteria API and Specification class. I have three methods that creates Specification for each of possible filter fields. Then I’m building dynamically filtering criterias based on the content of EmployeeFilter.
@Component
public class EmployeeQueryResolver implements GraphQLQueryResolver {
private EmployeeRepository repository;
EmployeeQueryResolver(EmployeeRepository repository) {
this.repository = repository;
}
// OTHER FIND METHODS ...
public Iterable<Employee&qt; employeesWithFilter(EmployeeFilter filter) {
Specification<Employee&qt; spec = null;
if (filter.getSalary() != null)
spec = bySalary(filter.getSalary());
if (filter.getAge() != null)
spec = (spec == null ? byAge(filter.getAge()) : spec.and(byAge(filter.getAge())));
if (filter.getPosition() != null)
spec = (spec == null ? byPosition(filter.getPosition()) :
spec.and(byPosition(filter.getPosition())));
if (spec != null)
return repository.findAll(spec);
else
return repository.findAll();
}
private Specification<Employee&qt; bySalary(FilterField filterField) {
return (Specification<Employee&qt;) (root, query, builder) -&qt; filterField.generateCriteria(builder, root.get("salary"));
}
private Specification<Employee&qt; byAge(FilterField filterField) {
return (Specification<Employee&qt;) (root, query, builder) -&qt; filterField.generateCriteria(builder, root.get("age"));
}
private Specification<Employee&qt; byPosition(FilterField filterField) {
return (Specification<Employee&qt;) (root, query, builder) -&qt; filterField.generateCriteria(builder, root.get("position"));
}
}
6. Testing Spring Boot GraphQL JPA support
We will insert some test data into the H2 database by defining data.sql inside src/main/resources directory.
insert into organization (id, name) values (1, 'Test1');
insert into organization (id, name) values (2, 'Test2');
insert into organization (id, name) values (3, 'Test3');
insert into organization (id, name) values (4, 'Test4');
insert into organization (id, name) values (5, 'Test5');
insert into department (id, name, organization_id) values (1, 'Test1', 1);
insert into department (id, name, organization_id) values (2, 'Test2', 1);
insert into department (id, name, organization_id) values (3, 'Test3', 1);
insert into department (id, name, organization_id) values (4, 'Test4', 2);
insert into department (id, name, organization_id) values (5, 'Test5', 2);
insert into department (id, name, organization_id) values (6, 'Test6', 3);
insert into department (id, name, organization_id) values (7, 'Test7', 4);
insert into department (id, name, organization_id) values (8, 'Test8', 5);
insert into department (id, name, organization_id) values (9, 'Test9', 5);
insert into employee (id, first_name, last_name, position, salary, age, department_id, organization_id) values (1, 'John', 'Smith', 'Developer', 10000, 30, 1, 1);
insert into employee (id, first_name, last_name, position, salary, age, department_id, organization_id) values (2, 'Adam', 'Hamilton', 'Developer', 12000, 35, 1, 1);
insert into employee (id, first_name, last_name, position, salary, age, department_id, organization_id) values (3, 'Tracy', 'Smith', 'Architect', 15000, 40, 1, 1);
insert into employee (id, first_name, last_name, position, salary, age, department_id, organization_id) values (4, 'Lucy', 'Kim', 'Developer', 13000, 25, 2, 1);
insert into employee (id, first_name, last_name, position, salary, age, department_id, organization_id) values (5, 'Peter', 'Wright', 'Director', 50000, 50, 4, 2);
insert into employee (id, first_name, last_name, position, salary, age, department_id, organization_id) values (6, 'Alan', 'Murray', 'Developer', 20000, 37, 4, 2);
insert into employee (id, first_name, last_name, position, salary, age, department_id, organization_id) values (7, 'Pamela', 'Anderson', 'Analyst', 7000, 27, 4, 2);
Now, we can easily perform some test queries by using GraphiQL that is embedded into our application and available under address http://localhost:8080/graphiql after startup. First, let’s verify the filtering query.
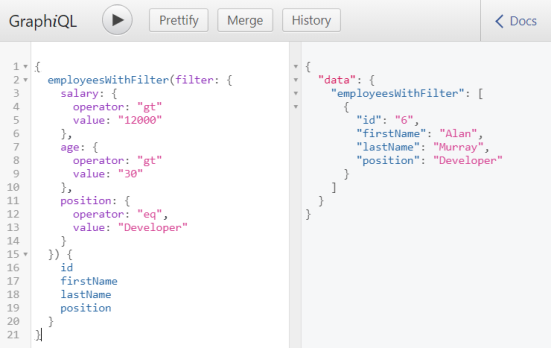
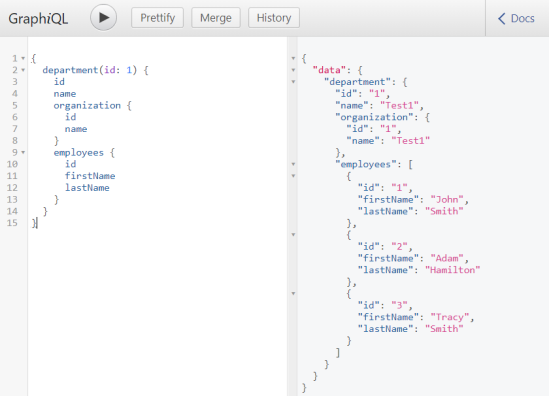
Now, we may test fetching by searching Department by id and fetching a list of employees and organization.



Related Posts