Generating large PDF files using JasperReports

During the last ‘Code Europe’ conference in Warsaw appeared many topics related to microservices architecture. Several times I heard the conclusion that the best candidate for separation from the monolith is service that generates PDF reports. It’s usually quite independent from the other parts of the application. I can see a similar approach in my organization, where the first microservice running in production mode was the one that generates PDF reports. To my surprise, the vendor which developed that microservice had to increase maximum heap size to 1GB on each of its instances. This has forced me to take a closer look at the topic of PDF reports generation process.
The most popular Java library for creating PDF files is JasperReports. During the generation process, this library by default stores all objects in RAM memory. If such reports are large, this could be a problem my vendor encountered. Their solution, as I have mentioned before, was to increase the maximum size of Java heap 🙂
This time, unlike usual, I’m going to start with the test implementation. Here’s a simple JUnit test with 20 requests per second sending to the service endpoint.
public class JasperApplicationTest {
protected Logger logger = Logger.getLogger(JasperApplicationTest.class.getName());
TestRestTemplate template = new TestRestTemplate();
@Test
public void testGetReport() throws InterruptedException {
List<HttpStatus> responses = new ArrayList<>();
Random r = new Random();
int i = 0;
for (; i < 20; i++) {
new Thread(new Runnable() {
@Override
public void run() {
int age = r.nextInt(99);
long start = System.currentTimeMillis();
ResponseEntity<InputStreamResource> res = template.getForEntity("http://localhost:2222/pdf/fv/{age}", InputStreamResource.class, age);
logger.info("Response (" + (System.currentTimeMillis()-start) + "): " + res.getStatusCode());
responses.add(res.getStatusCode());
try {
Thread.sleep(50);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}).start();
}
while (responses.size() != i) {
Thread.sleep(500);
}
logger.info("Test finished");
}
}
In my test scenario, I inserted about 1M records into the person table. Everything works fine during the running tests. Generated files had about 500kb size and 200 pages. All requests were succeeded and each of them had been processed about 8 seconds. In comparison with a single request which had been processed 4 seconds, it seems to be a good result. The situation with RAM is worse as you can see in the figure below. After generating 20 PDF reports allocated heap size increases to more than 1GB and used heap size was about 550MB. Also, CPU usage during report generation increased to 100% usage. I could easily image generating files bigger than 500kb in the production mode…
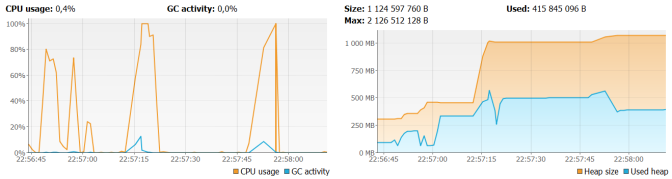
In our situation, we have two options. We can always add more RAM memory or … look for another choice 🙂 Jasper library comes with a handy solution – Virtualizers. The virtualizer cuts the jasper report print into different files and save them on the hard drive and/or compress it. There are three types of virtualizers:
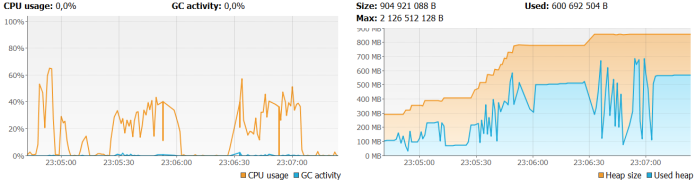
JRFileVirtualizer, JRSwapFileVirtualizer and JRGzipVirtualizer. You can read more about them here. Now, look at the figure below. Here’s an illustration of memory and CPU usage for the test with JRFileVirtualizer. It looks a little better than the previous figure, but it does not knock us down 🙂 However, requests with the same overload as for the previous test take much longer – about 30 seconds. It’s not a good message, but at least the heap size allocation is not increasing as fast as for the previous sample.
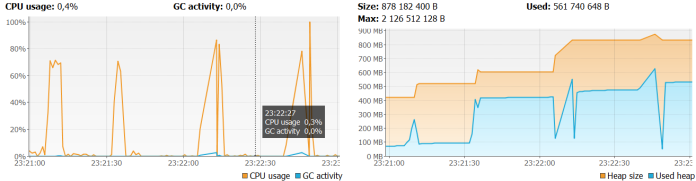
Same test has been performed for JRSwapFileVirtualizer. The requests were average processed around 10 seconds. The graph illustrating CPU and memory usage is rather more similar to in-memory test than JRFileVirtualizer test.
To see the difference between those three scenarios we have to run our application with a maximum heap size set. For my tests I set -Xmx128m -Xms128m. For a test with file virtualizers we receive HTTP responses with PDF reports, but for in-memory tests, the exception is thrown by the sample application: java.lang.OutOfMemoryError: GC overhead limit exceeded.
For testing purposes, I created the Spring Boot application. Sample source code is available as usual on GitHub. Here’s a full list of Maven dependencies for that project.
<dependency>
<groupId>net.sf.jasperreports</groupId>
<artifactId>jasperreports</artifactId>
<version>6.4.0</version>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-jpa</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<scope>runtime</scope>
</dependency>
Here’s application main class. There are @Bean declarations of file virtualizers and JasperReport which is responsible for template compilation from .jrxml file. To run application for testing purposes type java -jar -Xms64m -Xmx128m -Ddirectory=C:\Users\minkowp\pdf sample-jasperreport-boot.jar.
@SpringBootApplication
public class JasperApplication {
@Value("${directory}")
private String directory;
public static void main(String[] args) {
SpringApplication.run(JasperApplication.class, args);
}
@Bean
JasperReport report() throws JRException {
JasperReport jr = null;
File f = new File("personReport.jasper");
if (f.exists()) {
jr = (JasperReport) JRLoader.loadObject(f);
} else {
jr = JasperCompileManager.compileReport("src/main/resources/report.jrxml");
JRSaver.saveObject(jr, "personReport.jasper");
}
return jr;
}
@Bean
JRFileVirtualizer fileVirtualizer() {
return new JRFileVirtualizer(100, directory);
}
@Bean
JRSwapFileVirtualizer swapFileVirtualizer() {
JRSwapFile sf = new JRSwapFile(directory, 1024, 100);
return new JRSwapFileVirtualizer(20, sf, true);
}
}
There are three endpoints exposed for the tests:
/pdf/{age} – in memory PDF generation
/pdf/fv/{age} – PDF generation with JRFileVirtualizer
/pdf/sfv/{age} – PDF generation with JRSwapFileVirtualizer
Here’s a method generating a PDF report. Report is generated in fillReport static method from JasperFillManager. It takes three parameters as input: JasperReport which encapsulates compiled .jrxml template file, JDBC connection object and map of parameters. Then report is ganerated and saved on disk as a PDF file. File is returned as an attachement in the response.
private ResponseEntity<InputStreamResource> generateReport(String name, Map<String, Object> params) {
FileInputStream st = null;
Connection cc = null;
try {
cc = datasource.getConnection();
JasperPrint p = JasperFillManager.fillReport(jasperReport, params, cc);
JRPdfExporter exporter = new JRPdfExporter();
SimpleOutputStreamExporterOutput c = new SimpleOutputStreamExporterOutput(name);
exporter.setExporterInput(new SimpleExporterInput(p));
exporter.setExporterOutput(c);
exporter.exportReport();
st = new FileInputStream(name);
HttpHeaders responseHeaders = new HttpHeaders();
responseHeaders.setContentType(MediaType.valueOf("application/pdf"));
responseHeaders.setContentDispositionFormData("attachment", name);
responseHeaders.setContentLength(st.available());
return new ResponseEntity<InputStreamResource>(new InputStreamResource(st), responseHeaders, HttpStatus.OK);
} catch (Exception e) {
e.printStackTrace();
} finally {
fv.cleanup();
if (cc != null)
try {
cc.close();
} catch (SQLException e) {
e.printStackTrace();
}
}
return null;
}
To enable virtualizer during report generation we only have to pass one parameter to the map of parameters – an instance of virtualizer object.
@Autowired
JRFileVirtualizer fv;
@Value("${directory}")
private String directory;
@Autowired
DataSource datasource;
@Autowired
JasperReport jasperReport;
@ResponseBody
@RequestMapping(value = "/pdf/fv/{age}")
public ResponseEntity<InputStreamResource> getReportFv(@PathVariable("age") int age) {
logger.info("getReportFv(" + age + ")");
Map<String, Object> m = new HashMap<>();
m.put(JRParameter.REPORT_VIRTUALIZER, fv);
m.put("age", age);
String name = ++count + "personReport.pdf";
return generateReport(name, m);
}
Template file report.jrxml is available under /src/main/resources directory. Inside queryString tag there is SQL query which takes age parameter in WHERE statement. There are also five columns declared all taken from SQL query result.
<?xml version = "1.0" encoding = "UTF-8"?>
<!DOCTYPE jasperReport PUBLIC "//JasperReports//DTD Report Design//EN"
"http://jasperreports.sourceforge.net/dtds/jasperreport.dtd">
<jasperReport xmlns="http://jasperreports.sourceforge.net/jasperreports"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://jasperreports.sourceforge.net/jasperreports
http://jasperreports.sourceforge.net/xsd/jasperreport.xsd"
name="report2" pageWidth="595" pageHeight="842"
columnWidth="555" leftMargin="20" rightMargin="20"
topMargin="20" bottomMargin="20">
<parameter name="age" class="java.lang.Integer"/>
<queryString>
<![CDATA[SELECT * FROM person WHERE age = $P{age}]]>
</queryString>
<field name="id" class="java.lang.Integer" />
<field name="first_name" class="java.lang.String" />
<field name="last_name" class="java.lang.String" />
<field name="age" class="java.lang.Integer" />
<field name="pesel" class="java.lang.String" />
<detail>
<band height="15">
<textField>
<reportElement x="0" y="0" width="50" height="15" />
<textElement textAlignment="Right" verticalAlignment="Middle"/>
<textFieldExpression class="java.lang.Integer">
<![CDATA[$F{id}]]>
</textFieldExpression>
</textField>
<textField>
<reportElement x="100" y="0" width="80" height="15" />
<textElement textAlignment="Left" verticalAlignment="Middle"/>
<textFieldExpression class="java.lang.String">
<![CDATA[$F{first_name}]]>
</textFieldExpression>
</textField>
<textField>
<reportElement x="200" y="0" width="80" height="15" />
<textElement textAlignment="Left" verticalAlignment="Middle"/>
<textFieldExpression class="java.lang.String">
<![CDATA[$F{last_name}]]>
</textFieldExpression>
</textField>
<textField>
<reportElement x="300" y="0" width="50" height="15"/>
<textElement textAlignment="Right" verticalAlignment="Middle"/>
<textFieldExpression class="java.lang.Integer">
<![CDATA[$F{age}]]>
</textFieldExpression>
</textField>
<textField>
<reportElement x="380" y="0" width="80" height="15" />
<textElement textAlignment="Left" verticalAlignment="Middle"/>
<textFieldExpression class="java.lang.String">
<![CDATA[$F{pesel}]]>
</textFieldExpression>
</textField>
</band>
</detail>
</jasperReport>
And the last thing we have to do is to properly set database connection pool settings. A natural choice for the Spring Boot application is the Tomcat JDBC pool.
spring:
application:
name: jasper-service
datasource:
url: jdbc:mysql://192.168.99.100:33306/datagrid?useSSL=false
username: datagrid
password: datagrid
tomcat:
initial-size: 20
max-active: 30
Final words
In this article, I showed you how to avoid out of memory exception while generating large PDF reports with JasperReports. I compared three solutions: in-memory generation and two methods based on cutting the jasper print into different files and save them on the hard drive. For me, the most interesting was the solution based on a single swapped file with JRSwapFileVirtualizer. It is slower a little than an in-memory generation but works faster than similar tests for JRFileVirtualizer and in contrast to in-memory generation didn’t avoid an out of memory exception for files larger than 500kb with 20 requests per second.



Related Posts