Hazelcast with Spring Boot on Kubernetes

Hazelcast is the leading in-memory data grid (IMDG) solution. The main idea behind IMDG is to distribute data across many nodes inside a cluster. Therefore, it seems to be an ideal solution for running on a cloud platform like Kubernetes, where you can easily scale up or scale down a number of running instances. Since Hazelcast is written in Java you can easily integrate it with your Java application using standard libraries. Something that can also simplify a start with Hazelcast is Spring Boot. You may also use an unofficial library implementing Spring Repositories pattern for Hazelcast – Spring Data Hazelcast.
The main goal of this article is to demonstrate how to embed Hazelcast into the Spring Boot application and run it on Kubernetes as a multi-instance cluster. Thanks to Spring Data Hazelcast we won’t have to get into the details of Hazelcast data types. Although Spring Data Hazelcast does not provide many advanced features, it is very good for a start.
Architecture
We are running multiple instances of a single Spring Boot application on Kubernetes. Each application exposes port 8080 for HTTP API access and 5701 for Hazelcast cluster members discovery. Hazelcast instances are embedded into Spring Boot applications. We are creating two services on Kubernetes. The first of them is dedicated for HTTP API access, while the second is responsible for enabling discovery between Hazelcast instances. HTTP API will be used for making some tests requests that add data to the cluster and find data there. Let’s proceed to the implementation.
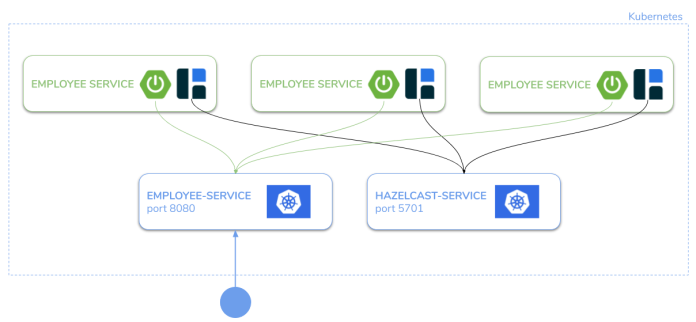
Example
The source code with sample application is as usual available on GitHub. It is available here https://github.com/piomin/sample-hazelcast-spring-datagrid.git. You should access module employee-kubernetes-service.
Dependencies
An integration between Spring and Hazelcast is provided by hazelcast-spring library. The version of Hazelcast libraries is related to Spring Boot via dependency management, so we just need to define the version of Spring Boot to the newest stable 2.2.4.RELEASE. The current version of Hazelcast related to this version of Spring Boot is 3.12.5. In order to enable Hazelcast members discovery on Kubernetes we also need to include hazelcast-kubernetes dependency. Its versioning is independable from core libraries. The newest version 2.0 is dedicated for Hazelcast 4. Since we are still using Hazelcast 3 we are declaring version 1.5.2 of hazelcast-kubernetes. We also include Spring Data Hazelcast and optionally Lombok for simplification.
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>2.2.4.RELEASE</version>
</parent>
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>com.hazelcast</groupId>
<artifactId>spring-data-hazelcast</artifactId>
<version>2.2.2</version>
</dependency>
<dependency>
<groupId>com.hazelcast</groupId>
<artifactId>hazelcast-spring</artifactId>
</dependency>
<dependency>
<groupId>com.hazelcast</groupId>
<artifactId>hazelcast-client</artifactId>
</dependency>
<dependency>
<groupId>com.hazelcast</groupId>
<artifactId>hazelcast-kubernetes</artifactId>
<version>1.5.2</version>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
</dependency>
</dependencies>
Enabling Kubernetes Discovery for Hazelcast
After including required dependencies Hazelcast has been enabled for our application. The only thing we need to do is to enable discovery through Kubernetes. The HazelcastInstance bean is already available in the context, so we may change its configuration by defining com.hazelcast.config.Config bean. We need to disable multicast discovery, which is enabled by default, and enable Kubernetes discovery in the network config as shown below. Kubernetes config requires setting a target namespace of Hazelcast deployment and its service name.
@Bean
Config config() {
Config config = new Config();
config.getNetworkConfig().getJoin().getTcpIpConfig().setEnabled(false);
config.getNetworkConfig().getJoin().getMulticastConfig().setEnabled(false);
config.getNetworkConfig().getJoin().getKubernetesConfig().setEnabled(true)
.setProperty("namespace", "default")
.setProperty("service-name", "hazelcast-service");
return config;
}
We also have to define Kubernetes Service hazelcast-service on port 5701. It is referenced to employee-service deployment.
apiVersion: v1
kind: Service
metadata:
name: hazelcast-service
spec:
selector:
app: employee-service
ports:
- name: hazelcast
port: 5701
type: LoadBalancer
Here’s Kubernetes Deployment and Service definition for our sample application. We are setting three replicas for our deployment. We are also exposing two ports outside containers.
apiVersion: apps/v1
kind: Deployment
metadata:
name: employee-service
labels:
app: employee-service
spec:
replicas: 3
selector:
matchLabels:
app: employee-service
template:
metadata:
labels:
app: employee-service
spec:
containers:
- name: employee-service
image: piomin/employee-service
ports:
- name: http
containerPort: 8080
- name: multicast
containerPort: 5701
---
apiVersion: v1
kind: Service
metadata:
name: employee-service
labels:
app: employee-service
spec:
ports:
- port: 8080
protocol: TCP
selector:
app: employee-service
type: NodePort
In fact, that’s all that needs to be done to succesfully run Hazelcast cluster on Kubernetes. Before proceeding to the deployment let’s take a look on the application implementation details.
Implementation
Our application is very simple. It defines a single model object, which is stored in Hazelcast cluster. Such a class needs to have id – a field annotated with Spring Data @Id, and should implement Seriazable interface.
@Getter
@Setter
@EqualsAndHashCode
@ToString
public class Employee implements Serializable {
@Id
private Long id;
@EqualsAndHashCode.Exclude
private Integer personId;
@EqualsAndHashCode.Exclude
private String company;
@EqualsAndHashCode.Exclude
private String position;
@EqualsAndHashCode.Exclude
private int salary;
}
With Spring Data Hazelcast we may define repositories without using any queries or Hazelcast specific API for queries. We are using a well-known method naming pattern defined by Spring Data to build find methods as shown below. Our repository interface should extend HazelcastRepository.
public interface EmployeeRepository extends HazelcastRepository<Employee, Long> {
Employee findByPersonId(Integer personId);
List<Employee> findByCompany(String company);
List<Employee> findByCompanyAndPosition(String company, String position);
List<Employee> findBySalaryGreaterThan(int salary);
}
To enable Spring Data Hazelcast Repositories we should annotate the main class or the configuration class with @EnableHazelcastRepositories.
@SpringBootApplication
@EnableHazelcastRepositories
public class EmployeeApplication {
public static void main(String[] args) {
SpringApplication.run(EmployeeApplication.class, args);
}
}
Finally, here’s the Spring controller implementation. It allows us to invoke all the find methods defined in the repository, add new Employee object to Hazelcast and remove the existing one.
@RestController
@RequestMapping("/employees")
public class EmployeeController {
private static final Logger logger = LoggerFactory.getLogger(EmployeeController.class);
private EmployeeRepository repository;
EmployeeController(EmployeeRepository repository) {
this.repository = repository;
}
@GetMapping("/person/{id}")
public Employee findByPersonId(@PathVariable("id") Integer personId) {
logger.info("findByPersonId({})", personId);
return repository.findByPersonId(personId);
}
@GetMapping("/company/{company}")
public List<Employee> findByCompany(@PathVariable("company") String company) {
logger.info(String.format("findByCompany({})", company));
return repository.findByCompany(company);
}
@GetMapping("/company/{company}/position/{position}")
public List<Employee> findByCompanyAndPosition(@PathVariable("company") String company, @PathVariable("position") String position) {
logger.info(String.format("findByCompany({}, {})", company, position));
return repository.findByCompanyAndPosition(company, position);
}
@GetMapping("/{id}")
public Employee findById(@PathVariable("id") Long id) {
logger.info("findById({})", id);
return repository.findById(id).get();
}
@GetMapping("/salary/{salary}")
public List<Employee> findBySalaryGreaterThan(@PathVariable("salary") int salary) {
logger.info(String.format("findBySalaryGreaterThan({})", salary));
return repository.findBySalaryGreaterThan(salary);
}
@PostMapping
public Employee add(@RequestBody Employee emp) {
logger.info("add({})", emp);
return repository.save(emp);
}
@DeleteMapping("/{id}")
public void delete(@PathVariable("id") Long id) {
logger.info("delete({})", id);
repository.deleteById(id);
}
}
Running Hazelcast on Kubernetes via Minikube
We will test our sample application on Minikube.
$ minikube start --vm-driver=virtualbox
The application is configured to run with Skaffold and Jib Maven Plugin. I have already described both these tools in one of my previous articles. They simplify the build and deployment process on Minikube. Assuming we are in the root directory of our application we just need to run the following command. Skaffold automatically builds our application using Maven, creates a Docker image based on Maven settings, applies a deployment file from k8s directory, and finally runs the application on Kubernetes.
$ skaffold dev
Since, we have declared three instances of our application in the deployment.yaml three pods are started. If Hazelcast discovery is succesfully finished you should see the following fragment of pods logs printed out by Skaffold.
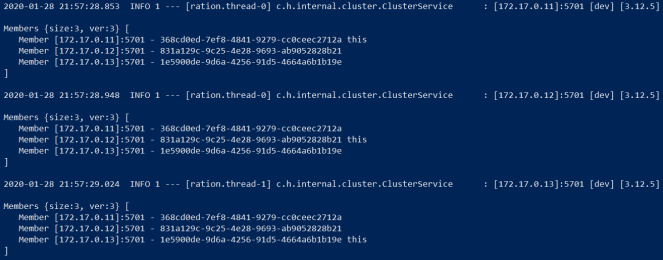
Let’s take a look at the running pods.

And the list of services. HTTP API is available outside Minikube under port 32090.

Now, we may send some test requests. We will start by calling POST /employees method to add some Employee objects into Hazelcast cluster. Then we will perform some find methods using GET /employees/{id}. Since all the methods have finished succesfully, we should take a look at the logs that clearly show the working of Hazelcast cluster.
$ curl -X POST http://192.168.99.100:32090/employees -d '{"id":1,"personId":1,"company":"Test1","position":"Developer","salary":2000}' -H "Content-Type: application/json"
{"id":1,"personId":1,"company":"Test1","position":"Developer","salary":2000}
$ curl -X POST http://192.168.99.100:32090/employees -d '{"id":2,"personId":2,"company":"Test2","position":"Developer","salary":5000}' -H "Content-Type: application/json"
{"id":2,"personId":2,"company":"Test2","position":"Developer","salary":5000}
$ curl -X POST http://192.168.99.100:32090/employees -d '{"id":3,"personId":3,"company":"Test2","position":"Developer","salary":5000}' -H "Content-Type: application/json"
{"id":3,"personId":3,"company":"Test2","position":"Developer","salary":5000}
$ curl -X POST http://192.168.99.100:32090/employees -d '{"id":4,"personId":4,"company":"Test3","position":"Developer","salary":9000}' -H "Content-Type: application/json"
{"id":4,"personId":4,"company":"Test3","position":"Developer","salary":9000}
$ curl http://192.168.99.100:32090/employees/1
{"id":1,"personId":1,"company":"Test1","position":"Developer","salary":2000}
$ curl http://192.168.99.100:32090/employees/2
{"id":2,"personId":2,"company":"Test2","position":"Developer","salary":5000}
$ curl http://192.168.99.100:32090/employees/3
{"id":3,"personId":3,"company":"Test2","position":"Developer","salary":5000}
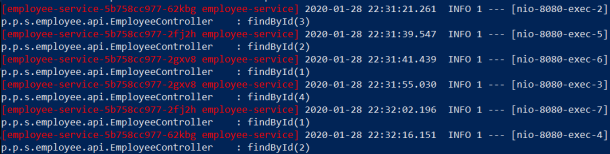
Here’s the screen with logs from pods printed out by Skaffold. Skaffold prints pod id for every single log line. Let’s take a closer look on the logs. The request for adding Employee with id=1 is processed by the application running on pod 5b758cc977-s6ptd. When we call find method using id=1 it is processed by the application on pod 5b758cc977-2fj2h. It proves that the Hazelcast cluster works properly. The same behaviour may be observed for other test requests.
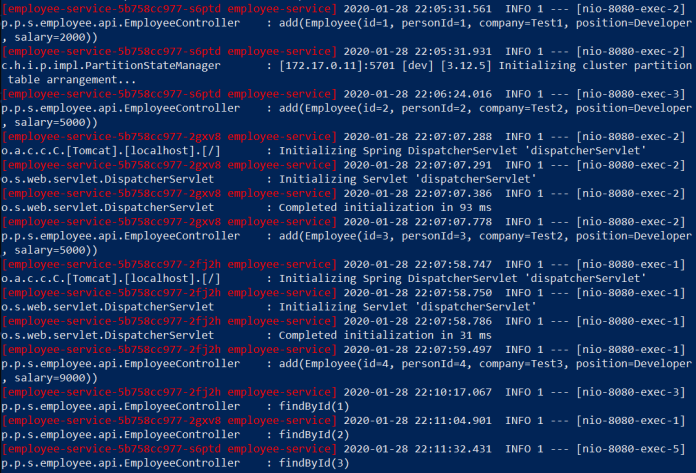
We may also call some other find methods.
$ curl http://192.168.99.100:32090/employees/company/Test2/position/Developer
[{"id":2,"personId":2,"company":"Test2","position":"Developer","salary":5000},{"id":3,"personId":3,"company":"Test2","position":"Developer","salary":5000}]
$ curl http://192.168.99.100:32090/employees/salary/3000
[{"id":2,"personId":2,"company":"Test2","position":"Developer","salary":5000},{"id":4,"personId":4,"company":"Test3","position":"Developer","salary":9000},{"id":3,"personId":3,"company":"Test2","position":"Developer","salary":5000}]
Let’s test another scenario. We will remove one pod from the cluster as shown below.
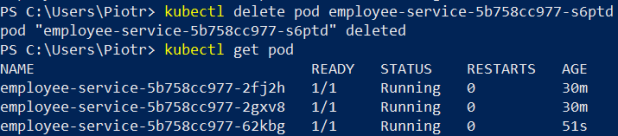
Then we send some test requests to GET /employees/{id}. No matter which instance of the application is processing the request the object is being returned.



Related Posts