Performance Comparison Between Spring MVC vs Spring WebFlux with Elasticsearch

Since Spring 5 and Spring Boot 2, there is full support for reactive REST API with the Spring WebFlux project. Also, project Spring Data systematically includes support for reactive NoSQL databases, and recently for SQL databases too. Since Spring Data Moore we can take advantage of reactive template and repository for Elasticsearch, what I have already described in one of my previous article Reactive Elasticsearch With Spring Boot.
Recently, we can observe the rising popularity of reactive programming and reactive APIs. This fact has led me to perform some comparison between synchronous API built on top of Spring MVC vs Spring WebFlux reactive API. The comparison will cover server-side memory usage and an average response time on the client-side. We will also use Spring Data Elasticsearch Repositories accessed by the controller for integration with a running instance of Elasticsearch on a Docker container. To make the test objective we will of course use the same versions of Spring Boot and Spring Data projects. First, let’s consider some prerequisites.
1. Dependencies
We are using Spring Boot in version 2.2.0.RELEASE with JDK 11.
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>2.2.0.RELEASE</version>
<relativePath/>
</parent>
<properties>
<java.version>11</java.version>
</properties>
Here’s the list of dependencies for the application with synchronous REST API:
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-elasticsearch</artifactId>
</dependency>
And here’s for the application reactive API:
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-webflux</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-elasticsearch</artifactId>
</dependency>
2. Running Elasticsearch
We will run the same Docker container for both tests. The container is started in development mode as a single node.
$ docker run -d --name elasticsearch -p 9200:9200 -p 9300:9300 -e "discovery.type=single-node" elasticsearch:6.6.2
We will insert the initial set of data into Elasticsearch.
public class SampleDataSet {
private static final Logger LOGGER = LoggerFactory.getLogger(SampleDataSet.class);
private static final String INDEX_NAME = "sample";
private static final String INDEX_TYPE = "employee";
private static int COUNTER = 0;
@Autowired
ElasticsearchTemplate template;
@Autowired
TaskExecutor taskExecutor;
@PostConstruct
public void init() {
if (!template.indexExists(INDEX_NAME)) {
template.createIndex(INDEX_NAME);
LOGGER.info("New index created: {}", INDEX_NAME);
}
for (int i = 0; i < 10000; i++) {
taskExecutor.execute(() -> bulk());
}
}
public void bulk() {
try {
ObjectMapper mapper = new ObjectMapper();
List<IndexQuery> queries = new ArrayList<>();
List<Employee> employees = employees();
for (Employee employee : employees) {
IndexQuery indexQuery = new IndexQuery();
indexQuery.setSource(mapper.writeValueAsString(employee));
indexQuery.setIndexName(INDEX_NAME);
indexQuery.setType(INDEX_TYPE);
queries.add(indexQuery);
}
if (queries.size() > 0) {
template.bulkIndex(queries);
}
template.refresh(INDEX_NAME);
LOGGER.info("BulkIndex completed: {}", ++COUNTER);
} catch (Exception e) {
LOGGER.error("Error bulk index", e);
}
}
private List<Employee> employees() {
List<Employee> employees = new ArrayList<>();
for (int i = 0; i < 10000; i++) {
Random r = new Random();
Employee employee = new Employee();
employee.setName("JohnSmith" + r.nextInt(1000000));
employee.setAge(r.nextInt(100));
employee.setPosition("Developer");
int departmentId = r.nextInt(500000);
employee.setDepartment(new Department((long) departmentId, "TestD" + departmentId));
int organizationId = departmentId / 100;
employee.setOrganization(new Organization((long) organizationId, "TestO" + organizationId, "Test Street No. " + organizationId));
employees.add(employee);
}
return employees;
}
}
We are testing a single document Employee:
@Document(indexName = "sample", type = "employee")
public class Employee {
@Id
private String id;
@Field(type = FieldType.Object)
private Organization organization;
@Field(type = FieldType.Object)
private Department department;
private String name;
private int age;
private String position;
}
I think that a set of data shouldn’t be too large, but also not too small. Let’s test node with around 18M of documents divided into 5 shards.
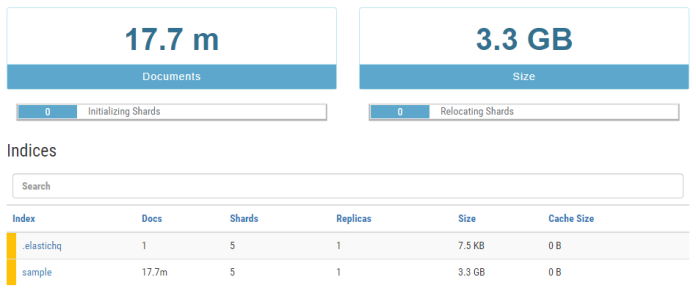
3. Synchronous API Tests
The library used for performance tests is junit-benchmarks. It allows to define the number of concurrent threads for JUnit test method, and the number of repeats.
<dependency>
<groupId>com.carrotsearch</groupId>
<artifactId>junit-benchmarks</artifactId>
<version>0.7.2</version>
<scope>test</scope>
</dependency>
The implementation of JUnit test class is visible below. It should extends AbstractBenchmark class and define the test rule BenchmarkRule. The tests are performed on the running external application available under localhost:8080 using TestRestTemplate. We have three test scenarios. In the first implementation inside addTest we are verifying a time required for adding a new document to Elasticsearch through POST method. Another two scenarios defined in methods findByNameTest and findByOrganizationNameTest tests search methods. Each test is running in 30 concurrent threads and repeated 500 times.
public class EmployeeRepositoryPerformanceTest extends AbstractBenchmark {
private static final Logger LOGGER = LoggerFactory.getLogger(EmployeeRepositoryPerformanceTest.class);
@Rule
public TestRule benchmarkRun = new BenchmarkRule();
private TestRestTemplate template = new TestRestTemplate();
private Random r = new Random();
@Test
@BenchmarkOptions(concurrency = 30, benchmarkRounds = 500, warmupRounds = 2)
public void addTest() {
Employee employee = new Employee();
employee.setName("John Smith");
employee.setAge(r.nextInt(100));
employee.setPosition("Developer");
employee.setDepartment(new Department((long) r.nextInt(1000), "TestD"));
employee.setOrganization(new Organization((long) r.nextInt(100), "TestO", "Test Street No. 1"));
employee = template.postForObject("http://localhost:8080/employees", employee, Employee.class);
Assert.assertNotNull(employee);
Assert.assertNotNull(employee.getId());
}
@Test
@BenchmarkOptions(concurrency = 30, benchmarkRounds = 500, warmupRounds = 2)
public void findByNameTest() {
String name = "JohnSmith" + r.nextInt(1000000);
Employee[] employees = template.getForObject("http://localhost:8080/employees/{name}", Employee[].class, name);
LOGGER.info("Found: {}", employees.length);
Assert.assertNotNull(employees);
}
@Test
@BenchmarkOptions(concurrency = 30, benchmarkRounds = 500, warmupRounds = 2)
public void findByOrganizationNameTest() {
String organizationName = "TestO" + r.nextInt(5000);
Employee[] employees = template.getForObject("http://localhost:8080/employees/organization/{organizationName}", Employee[].class, organizationName);
LOGGER.info("Found: {}", employees.length);
Assert.assertNotNull(employees);
}
}
4. Reactive API Tests
For reactive API we have the same scenarios, but they have to be implemented a little differently since we have asynchronous, non-blocking API. First, we will use a smart library called concurrentunit for testing multi-threaded or asynchronous code.
<dependency>
<groupId>net.jodah</groupId>
<artifactId>concurrentunit</artifactId>
<version>0.4.6</version>
<scope>test</scope>
</dependency>
ConcurrentUnit library allows us to define the Waiter object which is responsible for performing assertions and waiting for operations in any thread, and then notifying back the main test thread. Also we are using WebClient, which is able to retrieve reactive streams defined as Flux and Mono.
public class EmployeeRepositoryPerformanceTest {
private static final Logger LOGGER = LoggerFactory.getLogger(EmployeeRepositoryPerformanceTest.class);
@Rule
public TestRule benchmarkRun = new BenchmarkRule();
private final Random r = new Random();
private final WebClient client = WebClient.builder()
.baseUrl("https://localhost:8080")
.defaultHeader(HttpHeaders.CONTENT_TYPE, "application/json")
.build();
@Test
@BenchmarkOptions(concurrency = 30, benchmarkRounds = 500, warmupRounds = 2)
public void addTest() throws TimeoutException, InterruptedException {
final Waiter waiter = new Waiter();
Employee employee = new Employee();
employee.setName("John Smith");
employee.setAge(r.nextInt(100));
employee.setPosition("Developer");
employee.setDepartment(new Department((long) r.nextInt(10), "TestD"));
employee.setOrganization(new Organization((long) r.nextInt(10), "TestO", "Test Street No. 1"));
Mono<Employee> empMono = client.post().uri("/employees").body(Mono.just(employee), Employee.class).retrieve().bodyToMono(Employee.class);
empMono.subscribe(employeeLocal -> {
waiter.assertNotNull(employeeLocal);
waiter.assertNotNull(employeeLocal.getId());
waiter.resume();
});
waiter.await(5000);
}
@Test
@BenchmarkOptions(concurrency = 30, benchmarkRounds = 500, warmupRounds = 2)
public void findByNameTest() throws TimeoutException, InterruptedException {
final Waiter waiter = new Waiter();
String name = "JohnSmith" + r.nextInt(1000000);
Flux<Employee> employees = client.get().uri("/employees/{name}", name).retrieve().bodyToFlux(Employee.class);
employees.count().subscribe(count -> {
waiter.assertTrue(count > 0);
waiter.resume();
LOGGER.info("Found({}): {}", name, count);
});
waiter.await(5000);
}
@Test
@BenchmarkOptions(concurrency = 30, benchmarkRounds = 500, warmupRounds = 2)
public void findByOrganizationNameTest() throws TimeoutException, InterruptedException {
final Waiter waiter = new Waiter();
String organizationName = "TestO" + r.nextInt(5000);
Flux<Employee> employees = client.get().uri("/employees/organization/{organizationName}", organizationName).retrieve().bodyToFlux(Employee.class);
employees.count().subscribe(count -> {
waiter.assertTrue(count > 0);
waiter.resume();
LOGGER.info("Found: {}", count);
});
waiter.await(5000);
}
}
5. Spring MVC vs Spring WebFlux – Test Results
After discussing some prerequisites and implementation details we may finally proceed to the tests. I think that the results are pretty interesting. Let’s begin with Spring MVC tests. Here are graphs that illustrate memory usage during the tests. The first of them shows heap memory usage.
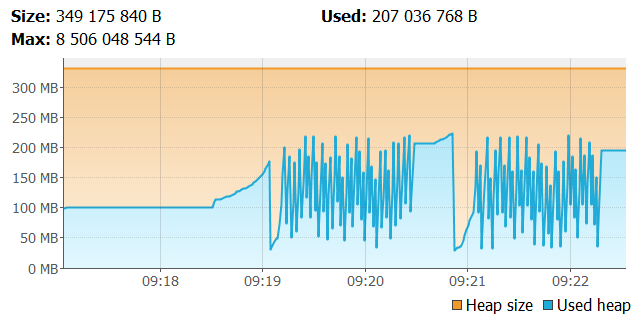
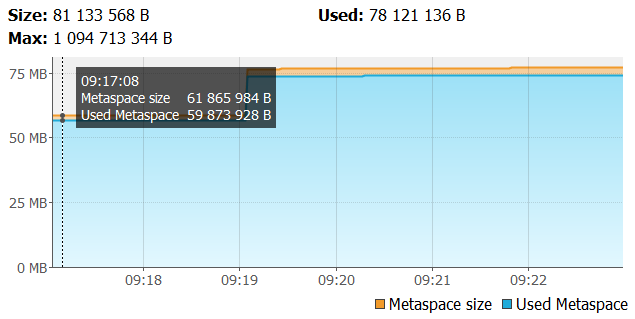
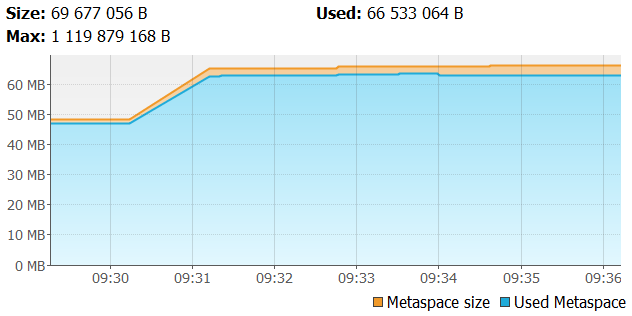
The second shows metaspace.
Here are equivalent graphs for reactive API tests. The heap memory usage is a little higher than for previous tests, although generally, Netty requires lower memory than Tomcat (50MB instead of 100MB before running the test).
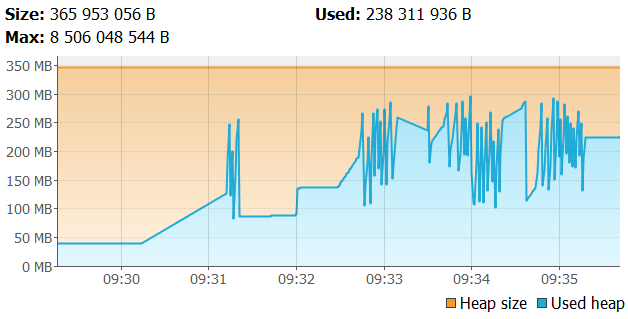
The metaspace usage is a little lower than for synchronous API tests (60MB vs 75MB).
And now the processing time test results. They may be a little unexpected. In fact, there is no big difference between synchronous and reactive tests. One thing that should be explained here. The method findByName returns a lower set of employees than findByOrganizationName. That’s why it is much faster than the method for searching by organization name.

As I mentioned before the results are pretty the same especially if thinking about the POST method. The result for findByName is 6.2s instead of 7.1s for synchronous calls, which gives a difference of around 15%. The test for findByOrganizationName has failed due to exceeding the 5s timeout defined for every single run of the test method. It seems that processing results around 3-4k of objects in a single response has significantly slowed down the sample application based on Spring WebFlux and reactive Elasticsearch repositories.

Summary
I won’t discuss the result of these tests. The thoughts are on your side. The source code repository is available on GitHub https://github.com/piomin/sample-spring-elasticsearch. Branch master contains a version for Spring MVC tests, while branch reactive for Spring WebFlux tests.



Related Posts