A Deep Dive Into Spring WebFlux Threading Model

If you are building reactive applications with Spring WebFlux, typically you will use Reactor Netty as a default embedded server. Reactor Netty is currently one of the most popular asynchronous event-driven frameworks. It provides non-blocking and backpressure-ready TCP, HTTP, and UDP clients and servers. In fact, the most important difference between synchronous and reactive frameworks is in their threading and concurrency model. Without understanding how reactive framework handles threads, you won’t fully understand reactivity. Let’s take a closer look on the threading model realized by Spring WebFlux and Project Reactor.
We should begin from the following fragment in Spring Framework Reference.
On a “vanilla” Spring WebFlux server (for example, no data access nor other optional dependencies), you can expect one thread for the server and several others for request processing (typically as many as the number of CPU cores).
So, the number of processing threads that handle incoming requests is related to the number of CPU cores. If you have 4 cores and you didn’t enable hyper-threading mechanism you would have 4 worker threads in the pool. You can determine the number of cores available to the JVM by using the static method, availableProcessors from class Runtime: Runtime.getRuntime().availableProcessors().
Example
At that moment, it is worth referring to the example application. It is a simple Spring Boot application that exposes reactive API built using Spring Webflux. The source code is available on GitHub: https://github.com/piomin/sample-spring-webflux.git. You can run it after building using java -jar command, or just simply run it from IDE. It also contains Dockerfile in the root directory, so you can build and run it inside a Docker container.
Limit CPU
With Docker you can easily limit the number of CPU cores “visible” for your application. When running a Docker container you just need to set parameter cpus as shown below.
$ docker run -d --name webflux --cpus="1" -p 8080:8080 piomin/sample-spring-webflux
The sample application is printing the number of available CPU cores during startup. Here’s the fragment of code responsible for it.
@SpringBootApplication
public class SampleSpringWebFluxApp {
private static final Logger LOGGER = LoggerFactory.getLogger(SampleSpringWebFluxApp.class);
public static void main(String[] args) {
SpringApplication.run(SampleSpringWebFluxApp.class, args);
}
@PostConstruct
public void init() {
LOGGER.info("CPU: {}", Runtime.getRuntime().availableProcessors());
}
}
Now, we can send some test requests to one of the available endpoints.
$ curl http://192.168.99.100:8080/persons/json
After that we may take a look at the logs generated by application using docker logs -f webflux command. The result is pretty unexpectable. We still have four worker threads in the pool, although the application uses only a single CPU core. Here’s the screen with application logs.
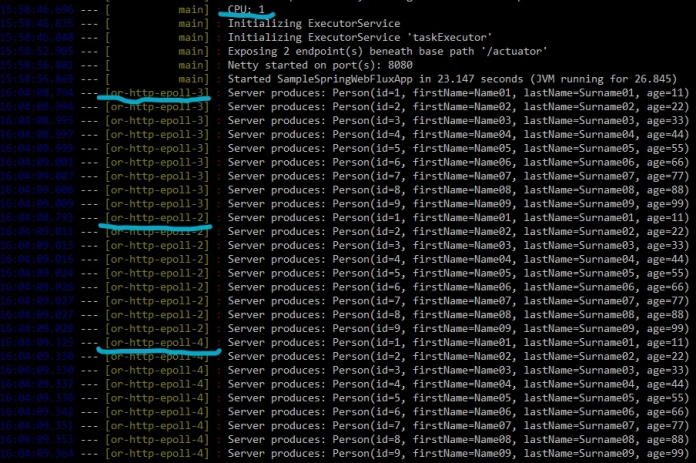
An explanation is pretty simple. Here’s the fragment of Reactor Netty source code that illustrates the algorithm used. The minimum number of worker threads in the pool is 4.

Well, it exactly explains why my application uses the same number of threads when it is running on my laptop with 4 CPUs, and on the Docker container which limits used CPU to a single core. You should also remember that Java is able to see the number of CPU cores inside a Docker container since version 10. If you use Java 8 on Docker your application sees the CPU on the machine not inside the container, which may have a huge impact on the consumed resources.
WebClient Thread Pool
Let’s consider the following implementation of reactive endpoint. First, we are emitting a stream of three Person objects, and then we are merging it with the stream returned by the WebClient.
@Autowired
WebClient client;
private Stream<Person> prepareStreamPart1() {
return Stream.of(
new Person(1, "Name01", "Surname01", 11),
new Person(2, "Name02", "Surname02", 22),
new Person(3, "Name03", "Surname03", 33)
);
}
@GetMapping("/integration/{param}")
public Flux<Person> findPersonsIntegration(@PathVariable("param") String param) {
return Flux.fromStream(this::prepareStreamPart1).log()
.mergeWith(
client.get().uri("/slow/" + param)
.retrieve()
.bodyToFlux(Person.class)
.log()
);
}
In order to properly understand what exactly happens with thread pool let’s recall the following fragment from Spring Framework Reference.
The reactive WebClient operates in event loop style. So you can see a small, fixed number of processing threads related to that (for example, reactor-http-nio- with the Reactor Netty connector). However, if Reactor Netty is used for both client and server, the two share event loop resources by default.
Typically, you have 4 worker threads, which are shared between both server processing and client-side communication with other resources. Since, we have enabled detailed logging with log method, we may easily analyse step by step thread pooling for the single request sent to the test endpoint. The incoming request is being processed by reactor-http-nio-2 thread. Then WebClient is called and it subscribes to the result stream in the same thread. But the result is published on the different thread reactor-http-nio-3, a first available in the pool.
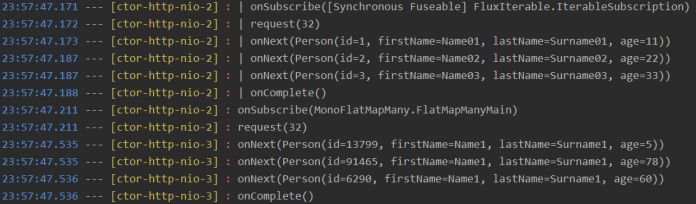
We can also analyze the subsequent logs for a single selected thread. In the following fragment of logs for thread reactor-http-nio-1 you may see that WebClient does not block the thread while waiting for a result from a calling resource. The method onComplete is called here for times in row without any onSubscribe call. The idea of non-blocking threads is the main concept around reactive programming, which allows us to handle many requests using relatively small numbers of threads (4 in that case).
15:02:25.875 --- [ctor-http-nio-1] : onSubscribe(MonoFlatMapMany.FlatMapManyMain)
15:02:25.875 --- [ctor-http-nio-1] : request(32)
15:02:25.891 --- [ctor-http-nio-1] : | onSubscribe([Synchronous Fuseable] FluxIterable.IterableSubscription)
15:02:25.891 --- [ctor-http-nio-1] : | request(32)
15:02:25.891 --- [ctor-http-nio-1] : | onNext(Person(id=1, firstName=Name01, lastName=Surname01, age=11))
15:02:25.892 --- [ctor-http-nio-1] : | onNext(Person(id=2, firstName=Name02, lastName=Surname02, age=22))
15:02:25.892 --- [ctor-http-nio-1] : | onNext(Person(id=3, firstName=Name03, lastName=Surname03, age=33))
15:02:25.892 --- [ctor-http-nio-1] : | onComplete()
15:02:25.894 --- [ctor-http-nio-1] : onSubscribe(MonoFlatMapMany.FlatMapManyMain)
15:02:25.895 --- [ctor-http-nio-1] : request(32)
15:02:25.924 --- [ctor-http-nio-1] : | onSubscribe([Synchronous Fuseable] FluxIterable.IterableSubscription)
15:02:25.925 --- [ctor-http-nio-1] : | request(32)
15:02:25.925 --- [ctor-http-nio-1] : | onNext(Person(id=1, firstName=Name01, lastName=Surname01, age=11))
15:02:25.925 --- [ctor-http-nio-1] : | onNext(Person(id=2, firstName=Name02, lastName=Surname02, age=22))
15:02:25.925 --- [ctor-http-nio-1] : | onNext(Person(id=3, firstName=Name03, lastName=Surname03, age=33))
15:02:25.926 --- [ctor-http-nio-1] : | onComplete()
15:02:25.927 --- [ctor-http-nio-1] : onSubscribe(MonoFlatMapMany.FlatMapManyMain)
15:02:25.927 --- [ctor-http-nio-1] : request(32)
15:02:26.239 --- [ctor-http-nio-1] : onNext(Person(id=38483, firstName=Name6, lastName=Surname6, age=50))
15:02:26.241 --- [ctor-http-nio-1] : onNext(Person(id=59103, firstName=Name6, lastName=Surname6, age=6))
15:02:26.241 --- [ctor-http-nio-1] : onNext(Person(id=67587, firstName=Name6, lastName=Surname6, age=36))
15:02:26.242 --- [ctor-http-nio-1] : onComplete()
15:02:26.283 --- [ctor-http-nio-1] : onNext(Person(id=40006, firstName=Name2, lastName=Surname2, age=41))
15:02:26.284 --- [ctor-http-nio-1] : onNext(Person(id=94727, firstName=Name2, lastName=Surname2, age=79))
15:02:26.287 --- [ctor-http-nio-1] : onNext(Person(id=19891, firstName=Name2, lastName=Surname2, age=84))
15:02:26.287 --- [ctor-http-nio-1] : onComplete()
15:02:26.292 --- [ctor-http-nio-1] : onNext(Person(id=67550, firstName=Name14, lastName=Surname14, age=92))
15:02:26.293 --- [ctor-http-nio-1] : onNext(Person(id=85063, firstName=Name14, lastName=Surname14, age=76))
15:02:26.293 --- [ctor-http-nio-1] : onNext(Person(id=54572, firstName=Name14, lastName=Surname14, age=18))
15:02:26.293 --- [ctor-http-nio-1] : onComplete()
15:02:26.295 --- [ctor-http-nio-1] : onNext(Person(id=49896, firstName=Name16, lastName=Surname16, age=20))
15:02:26.295 --- [ctor-http-nio-1] : onNext(Person(id=85684, firstName=Name16, lastName=Surname16, age=39))
15:02:26.296 --- [ctor-http-nio-1] : onNext(Person(id=2605, firstName=Name16, lastName=Surname16, age=75))
15:02:26.296 --- [ctor-http-nio-1] : onComplete()
15:02:26.337 --- [ctor-http-nio-1] : | onSubscribe([Synchronous Fuseable] FluxIterable.IterableSubscription)
15:02:26.338 --- [ctor-http-nio-1] : | request(32)
15:02:26.339 --- [ctor-http-nio-1] : | onNext(Person(id=1, firstName=Name01, lastName=Surname01, age=11))
15:02:26.339 --- [ctor-http-nio-1] : | onNext(Person(id=2, firstName=Name02, lastName=Surname02, age=22))
15:02:26.339 --- [ctor-http-nio-1] : | onNext(Person(id=3, firstName=Name03, lastName=Surname03, age=33))
15:02:26.340 --- [ctor-http-nio-1] : | onComplete()
Long response time
If you are using WebClient for communication with other resources you should be able to handle a long response time. Of course WebClient does not block the thread, but sometimes it is desired to use another thread pool than the main worker thread pool shared with the server. To do that you should use publishOn method. Spring WebFlux provides thread pool abstractions called Schedulers. You may use it to create different concurrency strategies. If you prefer to have a full control of the minimum and maximum number of threads in the pool you should define your own task executor as shown below. The minimum size of the pool is 5, while the maximum size is 10.
@Bean
public ThreadPoolTaskExecutor taskExecutor() {
ThreadPoolTaskExecutor executor = new ThreadPoolTaskExecutor();
executor.setCorePoolSize(5);
executor.setMaxPoolSize(10);
executor.setQueueCapacity(100);
executor.setThreadNamePrefix("slow-");
executor.initialize();
return executor;
}
Then you just need to set it as a default scheduler for publishOn method. Here’s our second test endpoint that sets a dedicated thread pool for WebClient.
@GetMapping("/integration-in-different-pool/{param}")
public Flux<Person> findPersonsIntegrationInDifferentPool(@PathVariable("param") String param) {
return Flux.fromStream(this::prepareStreamPart1).log()
.mergeWith(
client.get().uri("/slow/" + param)
.retrieve()
.bodyToFlux(Person.class)
.log()
.publishOn(Schedulers.fromExecutor(taskExecutor))
);
}
Performance Testing
Now, our main goal is to compare performance of the both implemented endpoints. First of them using the same thread pool for server requests processing and for WebClient, while the second creates separate thread pool for WebClient with publishOn. The first step of preparing such a comparison test is to create a mock with delayed response. We will use MockWebServer provided by okhttp. It caches requests send to /slow/{param} endpoint, emits the stream with Person objects delayed 200 ms.
public static MockWebServer mockBackEnd;
@BeforeClass
public static void setUp() throws IOException {
final Dispatcher dispatcher = new Dispatcher() {
@NotNull
@Override
public MockResponse dispatch(@NotNull RecordedRequest recordedRequest) throws InterruptedException {
String pathParam = recordedRequest.getPath().replaceAll("/slow/", "");
List personsPart2 = List.of(new Person(r.nextInt(100000), "Name" + pathParam, "Surname" + pathParam, r.nextInt(100)),
new Person(r.nextInt(100000), "Name" + pathParam, "Surname" + pathParam, r.nextInt(100)),
new Person(r.nextInt(100000), "Name" + pathParam, "Surname" + pathParam, r.nextInt(100)));
try {
return new MockResponse()
.setResponseCode(200)
.setBody(mapper.writeValueAsString(personsPart2))
.setHeader("Content-Type", "application/json")
.setBodyDelay(200, TimeUnit.MILLISECONDS);
}
catch (JsonProcessingException e) {
e.printStackTrace();
}
return null;
}
};
mockBackEnd = new MockWebServer();
mockBackEnd.setDispatcher(dispatcher);
mockBackEnd.start();
System.setProperty("target.uri", "http://localhost:" + mockBackEnd.getPort());
}
@AfterClass
public static void tearDown() throws IOException {
mockBackEnd.shutdown();
}
The last step in our implementation is to create test methods. For calling both sample endpoints we can use synchronous TestRestTemplate, since it doesn’t impact on the results. For benchmarking I’m using junit-benchmarks library, which allows me to define the number of concurrent threads and maximum number of attempts. To enable that library for JUnit test we just need to define @Rule. Here’s the implementation of our performance test. We are running Spring Boot in test mode and then starting 50 concurrent threads with 300 attempts.
@SpringBootTest(webEnvironment = SpringBootTest.WebEnvironment.DEFINED_PORT)
@RunWith(SpringRunner.class)
public class PerformanceSpringWebFluxTest {
private static final Logger LOGGER = LoggerFactory.getLogger(PerformanceSpringWebFluxTest.class);
private static ObjectMapper mapper = new ObjectMapper();
private static Random r = new Random();
private static int i = 0;
@Rule
public TestRule benchmarkRun = new BenchmarkRule();
@Autowired
TestRestTemplate template;
@Test
@BenchmarkOptions(warmupRounds = 10, concurrency = 50, benchmarkRounds = 300)
public void testPerformance() throws InterruptedException {
ResponseEntity<Person[]> r = template.exchange("/persons/integration/{param}", HttpMethod.GET, null, Person[].class, ++i);
Assert.assertEquals(200, r.getStatusCodeValue());
Assert.assertNotNull(r.getBody());
Assert.assertEquals(6, r.getBody().length);
}
@Test
@BenchmarkOptions(warmupRounds = 10, concurrency = 50, benchmarkRounds = 300)
public void testPerformanceInDifferentPool() throws InterruptedException {
ResponseEntity<Person[]> r = template.exchange("/persons/integration-in-different-pool/{param}", HttpMethod.GET, null, Person[].class, ++i);
Assert.assertEquals(200, r.getStatusCodeValue());
Assert.assertNotNull(r.getBody());
Assert.assertEquals(6, r.getBody().length);
}
}
Here are the results. For an endpoint with a default Spring WebFlux threading model assuming a shareable thread pool between server processing and client requests there is ~5.5s for processing all 300 requests. For a method with a separate thread pool for WebClient we have ~2.9s for all 300 requests. In general, the more threads you will use in your thread the ratio of average processing time between first and second model would be changed in favor of the second model (with separate thread pool for client).

And the result for separated WebClient thread pool.

Using Spring Boot Actuator
Sometimes, you need to use some additional libraries in your WebFlux application. One of them is Spring Boot Actuator, which may be especially required if you have to expose health check or metrics endpoints. To find out how Spring WebFlux is handling threading for Spring Boot Actuator we will profile our application with YourKit. After running the application you should generate some traffic to /actuator/health endpoint. Here’s the screen with threads from YourKit. As you see a worker thread (reactor-http-nio-*) delegates long-running job threads available in bounded elastic pool (boundedElastic-*).
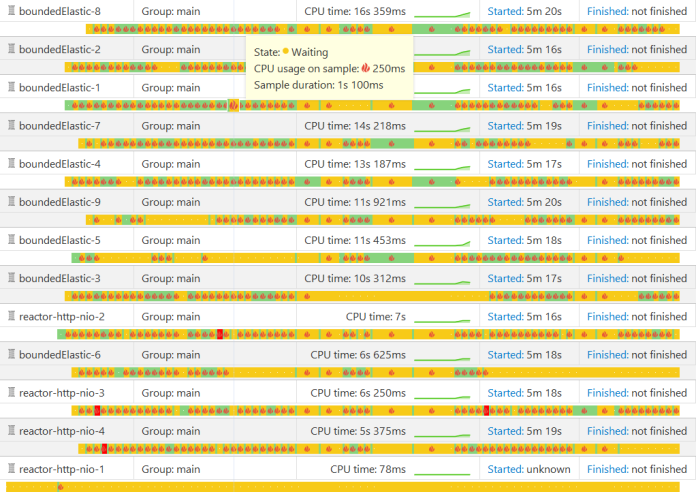
Threads from bounded elastic are checking free disk space, that is by default a part of Spring Boot Actuator /health endpoint.




Related Posts