Circuit breaker and retries on Kubernetes with Istio and Spring Boot

An ability to handle communication failures in an inter-service communication is an absolute necessity for every single service mesh framework. It includes handling of timeouts and HTTP error codes. In this article I’m going to show how to configure retry and circuit breaker mechanisms using Istio. The same as for the previous article about Istio Service mesh on Kubernetes with Istio and Spring Boot we will analyze a communication between two simple Spring Boot applications deployed on Kubernetes. But instead of very basic example we are going to discuss more advanced topics.
Example
For demonstrating usage of Istio and Spring Boot I created a repository on GitHub with two sample applications: callme-service and caller-service. The address of this repository is https://github.com/piomin/sample-istio-services.git. The same repository has been for the first article about service mesh with Istio already mentioned in the preface.
Architecture
The architecture of our sample system is pretty similar to those in the previous article. However, there are some differences. We are not injecting a fault or delay using Istio components, but directly on the application inside the source code. Why? Now, we will be able to handle directly the rules created for callme-service, not on the client side as before. Also we are running two instances of version v2 of callme-service application to test how circuit breaker works for more than instances of the same service (or rather the same Deployment). The following picture illustrates the currently described architecture.
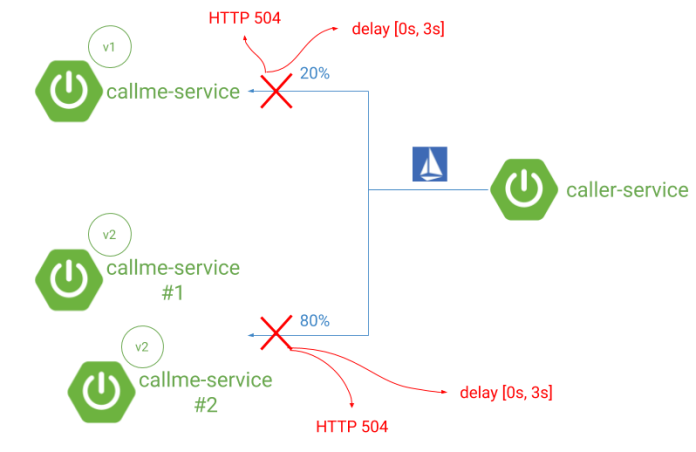
Spring Boot applications
We are starting from an implementation of the sample applications. The application callme-service is exposing two endpoints that return information about version and instance id. The endpoint GET /ping-with-random-error sets HTTP 504 error code as a response for ~50% of requests. The endpoint GET /ping-with-random-delay returns response with random delay between 0s and 3s. Here’s the implementation of @RestController on the callme-service side.
@RestController
@RequestMapping("/callme")
public class CallmeController {
private static final Logger LOGGER = LoggerFactory.getLogger(CallmeController.class);
private static final String INSTANCE_ID = UUID.randomUUID().toString();
private Random random = new Random();
@Autowired
BuildProperties buildProperties;
@Value("${VERSION}")
private String version;
@GetMapping("/ping-with-random-error")
public ResponseEntity<String> pingWithRandomError() {
int r = random.nextInt(100);
if (r % 2 == 0) {
LOGGER.info("Ping with random error: name={}, version={}, random={}, httpCode={}",
buildProperties.getName(), version, r, HttpStatus.GATEWAY_TIMEOUT);
return new ResponseEntity<>("Surprise " + INSTANCE_ID + " " + version, HttpStatus.GATEWAY_TIMEOUT);
} else {
LOGGER.info("Ping with random error: name={}, version={}, random={}, httpCode={}",
buildProperties.getName(), version, r, HttpStatus.OK);
return new ResponseEntity<>("I'm callme-service" + INSTANCE_ID + " " + version, HttpStatus.OK);
}
}
@GetMapping("/ping-with-random-delay")
public String pingWithRandomDelay() throws InterruptedException {
int r = new Random().nextInt(3000);
LOGGER.info("Ping with random delay: name={}, version={}, delay={}", buildProperties.getName(), version, r);
Thread.sleep(r);
return "I'm callme-service " + version;
}
}
The application caller-service is also exposing two GET endpoints. It is using RestTemplate to call the corresponding GET endpoints exposed by callme-service. It also returns the version of caller-service, but there is only a single Deployment of that application labeled with version=v1.
@RestController
@RequestMapping("/caller")
public class CallerController {
private static final Logger LOGGER = LoggerFactory.getLogger(CallerController.class);
@Autowired
BuildProperties buildProperties;
@Autowired
RestTemplate restTemplate;
@Value("${VERSION}")
private String version;
@GetMapping("/ping-with-random-error")
public ResponseEntity<String> pingWithRandomError() {
LOGGER.info("Ping with random error: name={}, version={}", buildProperties.getName(), version);
ResponseEntity<String> responseEntity =
restTemplate.getForEntity("http://callme-service:8080/callme/ping-with-random-error", String.class);
LOGGER.info("Calling: responseCode={}, response={}", responseEntity.getStatusCode(), responseEntity.getBody());
return new ResponseEntity<>("I'm caller-service " + version + ". Calling... " + responseEntity.getBody(), responseEntity.getStatusCode());
}
@GetMapping("/ping-with-random-delay")
public String pingWithRandomDelay() {
LOGGER.info("Ping with random delay: name={}, version={}", buildProperties.getName(), version);
String response = restTemplate.getForObject("http://callme-service:8080/callme/ping-with-random-delay", String.class);
LOGGER.info("Calling: response={}", response);
return "I'm caller-service " + version + ". Calling... " + response;
}
}
Handling retries in Istio
The definition of Istio DestinationRule is the same as before in my article Service mesh on Kubernetes with Istio and Spring Boot. There two subsets created for instances labeled with version=v1 and version=v2. Retries and timeout may be configured on VirtualService. We may set the number of retries and the conditions under which retry takes place (a list of enum strings). The following configuration is also setting 3s timeout for the whole request. Both these settings are available inside HTTPRoute object. We also need to set a timeout per single attempt. In that case I set 1s. How does it work in practice? We will analyze it in a simple example.
apiVersion: networking.istio.io/v1beta1
kind: DestinationRule
metadata:
name: callme-service-destination
spec:
host: callme-service
subsets:
- name: v1
labels:
version: v1
- name: v2
labels:
version: v2
---
apiVersion: networking.istio.io/v1beta1
kind: VirtualService
metadata:
name: callme-service-route
spec:
hosts:
- callme-service
http:
- route:
- destination:
host: callme-service
subset: v2
weight: 80
- destination:
host: callme-service
subset: v1
weight: 20
retries:
attempts: 3
perTryTimeout: 1s
retryOn: 5xx
timeout: 3s
Before deploying sample applications we should increase a level of logging. We may easily enable Istio access logging. Thanks to that Envoy proxies print access logs with all incoming requests and outgoing responses to their standard output. Analyze of logging entries will be especially usable for detecting retry attempts.
$ istioctl manifest apply --set profile=default --set meshConfig.accessLogFile="/dev/stdout"
Now, let’s send a test request to the HTTP endpoint GET /caller/ping-with-random-delay. It calls the randomly delayed callme-service endpoint GET /callme/ping-with-random-delay. Here’s the request and response for that operation.
![]()
Seemingly it’s a very clear situation. But let’s check out what is happening under the hood. I have highlighted the sequence of retries. As you see Istio has performed two retries, since the first two attempts were longer than perTryTimoeut which has been set to 1s. Both two attempts were timeout by Istio, which can be verified in its access logs. The third attempt was successful, since it took around 400ms.
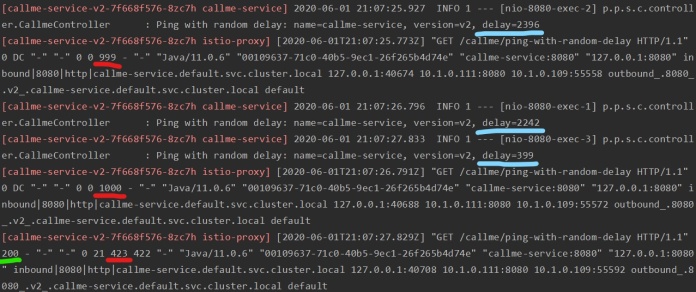
Retrying on timeout is not the only available option of retrying in Istio. In fact, we may retry all 5XX or even 4XX codes. The VirtualService for testing just error codes is much simpler, since we don’t have to configure any timeouts.
apiVersion: networking.istio.io/v1beta1
kind: VirtualService
metadata:
name: callme-service-route
spec:
hosts:
- callme-service
http:
- route:
- destination:
host: callme-service
subset: v2
weight: 80
- destination:
host: callme-service
subset: v1
weight: 20
retries:
attempts: 3
retryOn: gateway-error,connect-failure,refused-stream
We are going to call HTTP endpoint with GET /caller/ping-with-random-error, that is calling endpoint GET /callme/ping-with-random-error exposed by callme-service. It is returning HTTP 504 for around 50% of incoming requests. Here’s the request and successful response with 200 OK HTTP code.
![]()
Here are the logs, which illustrate what happened on the callme-service side. The requests have been retried 2 times, since the two first attempts result in HTTP error code.
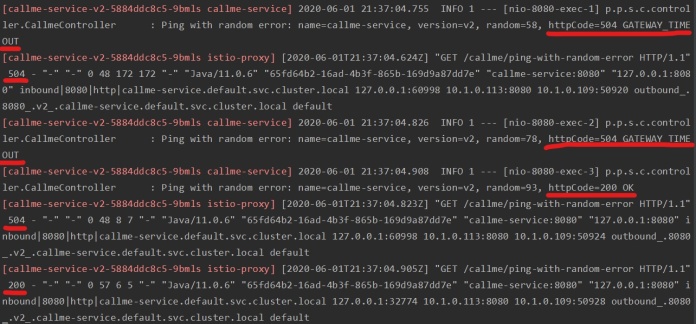
Istio circuit breaker
A circuit breaker is configured on the DestinationRule object. We are using TrafficPolicy for that. First we will not set any retries used for the previous sample, so we need to remove it from VirtualService definition. We should also disable any retries on the connectionPool inside TrafficPolicy. And now the most important. For configuring a circuit breaker in Istio we are using OutlierDetection object. Istio circuit breaker implementation is based on consecutive errors returned by the downstream service. The number of subsequent errors may be configured using properties consecutive5xxErrors or consecutiveGatewayErrors. The only difference between them is in the HTTP errors they are able to handle. While consecutiveGatewayErrors is just for 502, 503 and 504, the consecutive5xxErrors is used for 5XX codes. In the following configuration of callme-service-destination I used set consecutive5xxErrors on 3. It means that after 3 errors in row an instance (pod) of application is removed from load balancing for 1 minute (baseEjectionTime=1m). Because we are running two pods of callme-service in version v2 we also need to override a default value of maxEjectionPercent to 100%. A default value of that property is 10%, and it indicates a maximum % of hosts in the load balancing pool that can be ejected.
apiVersion: networking.istio.io/v1beta1
kind: DestinationRule
metadata:
name: callme-service-destination
spec:
host: callme-service
subsets:
- name: v1
labels:
version: v1
- name: v2
labels:
version: v2
trafficPolicy:
connectionPool:
http:
http1MaxPendingRequests: 1
maxRequestsPerConnection: 1
maxRetries: 0
outlierDetection:
consecutive5xxErrors: 3
interval: 30s
baseEjectionTime: 1m
maxEjectionPercent: 100
---
apiVersion: networking.istio.io/v1beta1
kind: VirtualService
metadata:
name: callme-service-route
spec:
hosts:
- callme-service
http:
- route:
- destination:
host: callme-service
subset: v2
weight: 80
- destination:
host: callme-service
subset: v1
weight: 20
The fastest way of deploying both applications is with Jib and Skaffold. First you go to directory callme-service and execute skaffold dev command with optional --port-forward parameter.
$ cd callme-service
$ skaffold dev --port-forward
Then do the same for caller-service.
$ cd caller-service
$ skaffold dev --port-forward
Before sending some test requests let’s run the second instance of v2 version of callme-service, since Deployment sets parameter replicas to 1. To do that we need to run the following command.
$ kubectl scale --replicas=2 deployment/callme-service-v2
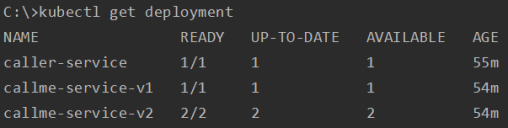
Now, let’s verify the status of deployment on Kubernetes. There are 3 deployments. The deployment callme-service-v2 has to running pods.
After that we are ready to send some test requests. We are calling endpoint GET /caller/ping-with-random-error exposed by caller-service, that is calling endpoint GET /callme/ping-with-random-error exposed by callme-service. Endpoint exposed by callme-service returns HTTP 504 for 50% of requests. I have already set port forwarding for callme-service on 8080, so the command used calling application is: curl http://localhost:8080/caller/ping-with-random-error.
Now, let’s analyze responses from caller-service. I have highlighted the responses with HTTP 504 error code from instance of callme-service with version v2 and generated id 98c068bb-8d02-4d2a-9999-23951bbed6ad. After 3 error responses in row from that instance, it is immediately removed from load balancing pool, what results in sending all other requests to the second instance of callme-service v2 having id 00653617-58e1-4d59-9e36-3f98f9d403b8. Of course there is still available a single instance of callme-service v1, that is receiving 20% of total requests send by caller-service.
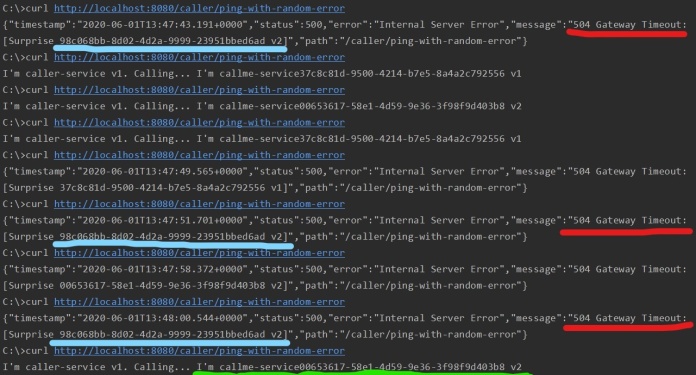
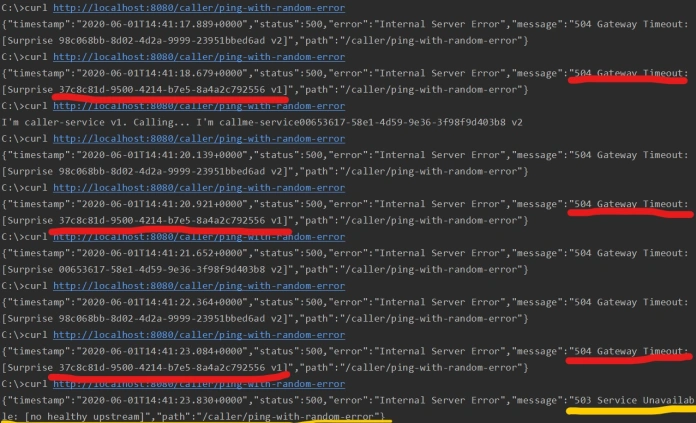
Ok, let’s check what will happen if a single instance callme-service v1 returns 3 errors in row. I have also highlighted those error responses in the picture with logs visible below. Because there is only one instance of callme-service v1 in the pool, there is no chance to redirect an incoming traffic to other instances. That’s why Istio is returning HTTP 503 for the next request sent to callme-service v1. The same response is returned within 1 next minute since the circuit is open.



Related Posts